
Hi Brad I used LVM2 to create the logical volume. I re-launched a new Galaxy Cloudman instance since I already removed the previous one. So, I have a LVM volume of 2 TB (1.8 TB netto) You can see this in the picture below, 1.5 TB available + 336 GB used = 1.8 TB. The error/warning = "Did not find a volume attached to instance i-xxxx as device 'None', file system 'galaxyData' (vols=[]" If I launch an extra node, the /mnt/galaxyData is nicely mounted onto the node ubuntu@ip-10-46-134-155:~$ df -h Filesystem Size Used Avail Use% Mounted on /dev/sda1 15G 12G 3.3G 79% / devtmpfs 3.7G 116K 3.7G 1% /dev none 3.8G 0 3.8G 0% /dev/shm none 3.8G 96K 3.8G 1% /var/run none 3.8G 0 3.8G 0% /var/lock none 3.8G 0 3.8G 0% /lib/init/rw /dev/sdb 414G 201M 393G 1% /mnt domU-12-31-39-0A-62-12.compute-1.internal:/mnt/galaxyData 1.9T 336G 1.5T 19% /mnt/galaxyData domU-12-31-39-0A-62-12.compute-1.internal:/mnt/galaxyTools 10G 1.7G 8.4G 17% /mnt/galaxyTools domU-12-31-39-0A-62-12.compute-1.internal:/mnt/galaxyIndices 700G 654G 47G 94% /mnt/galaxyIndices domU-12-31-39-0A-62-12.compute-1.internal:/opt/sge 15G 12G 3.3G 79% /opt/sge Uploading a file is OK but the "Grooming" results in following error (BTW this grooming succeeds in a "normal" Galaxy Cloudman setup on the same file with the same parameters used) WARNING:galaxy.datatypes.registry:Overriding conflicting datatype with extension 'coverage', using datatype from /mnt/galaxyData/tmp/tmpGx9fsi. I then moved the /mnt/galaxyData/tmp/tmpGx9fsi to /mnt/galaxyData/tmp/tmpGx9fsi.old but didn`t help. I restarted all services (Galaxy, SGE, PostgreSQL) ... SGE Log 02/15/2012 11:22:08| main|domU-12-31-39-0A-62-12|I|read job database with 0 entries in 0 seconds 02/15/2012 11:22:08| main|domU-12-31-39-0A-62-12|E|error opening file "/opt/sge/default/common/./sched_configuration" for reading: No such file or directory 02/15/2012 11:22:08| main|domU-12-31-39-0A-62-12|E|error opening file "/opt/sge/default/spool/qmaster/./sharetree" for reading: No such file or directory 02/15/2012 11:22:08| main|domU-12-31-39-0A-62-12|I|qmaster hard descriptor limit is set to 8192 02/15/2012 11:22:08| main|domU-12-31-39-0A-62-12|I|qmaster soft descriptor limit is set to 8192 02/15/2012 11:22:08| main|domU-12-31-39-0A-62-12|I|qmaster will use max. 8172 file descriptors for communication 02/15/2012 11:22:08| main|domU-12-31-39-0A-62-12|I|qmaster will accept max. 99 dynamic event clients 02/15/2012 11:22:08| main|domU-12-31-39-0A-62-12|I|starting up GE 6.2u5 (lx24-amd64) 02/15/2012 11:22:08| main|domU-12-31-39-0A-62-12|W|can't open job sequence number file "jobseqnum": for reading: No such file or directory -- guessing next number 02/15/2012 11:22:08| main|domU-12-31-39-0A-62-12|W|can't open ar sequence number file "arseqnum": for reading: No such file or directory -- guessing next number 02/15/2012 11:22:12|worker|domU-12-31-39-0A-62-12|E|adminhost "domU-12-31-39-0A-62-12.compute-1.internal" already exists 02/15/2012 11:22:13|worker|domU-12-31-39-0A-62-12|E|adminhost "domU-12-31-39-0A-62-12.compute-1.internal" already exists Uploaded my fastq file (OK) and trying to "Groom" GALAXY Log galaxy.jobs.runners.drmaa DEBUG 2012-02-15 11:30:53,425 (30) submitting file /mnt/galaxyTools/galaxy-central/database/pbs/galaxy_30.sh galaxy.jobs.runners.drmaa DEBUG 2012-02-15 11:30:53,425 (30) command is: python /mnt/galaxyTools/galaxy-central/tools/fastq/fastq_groomer.py '/mnt/galaxyData/files/000/dataset_58.dat' 'illumina' '/mnt/galaxyData/files/000/dataset_59.dat' 'sanger' 'ascii' 'summarize_input'; cd /mnt/galaxyTools/galaxy-central; /mnt/galaxyTools/galaxy-central/set_metadata.sh /mnt/galaxyData/files /mnt/galaxyData/tmp/job_working_directory/000/30 . /mnt/galaxyTools/galaxy-central/universe_wsgi.ini /mnt/galaxyData/tmp/tmp2GBeCB /mnt/galaxyData/tmp/job_working_directory/000/30/galaxy.json /mnt/galaxyData/tmp/job_working_directory/000/30/metadata_in_HistoryData setAssociation_59_Q8oYiT,/mnt/galaxyData/tmp/job_working_directory/000/3 0/metadata_kwds_HistoryDatasetAssociation_59_UXjfqE,/mnt/galaxyData/tmp/ job_working_directory/000/30/metadata_out_HistoryDatasetAssociation_59_q WHyc4,/mnt/galaxyData/tmp/job_working_directory/000/30/metadata_results_ HistoryDatasetAssociation_59_zGJk7G,,/mnt/galaxyData/tmp/job_working_dir ectory/000/30/metadata_override_HistoryDatasetAssociation_59_KjamX7 galaxy.jobs.runners.drmaa ERROR 2012-02-15 11:30:53,427 Uncaught exception queueing job Traceback (most recent call last): File "/mnt/galaxyTools/galaxy-central/lib/galaxy/jobs/runners/drmaa.py", line 133, in run_next self.queue_job( obj ) File "/mnt/galaxyTools/galaxy-central/lib/galaxy/jobs/runners/drmaa.py", line 213, in queue_job job_id = self.ds.runJob(jt) File "/mnt/galaxyTools/galaxy-central/eggs/drmaa-0.4b3-py2.6.egg/drmaa/__init __.py", line 331, in runJob _h.c(_w.drmaa_run_job, jid, _ct.sizeof(jid), jobTemplate) File "/mnt/galaxyTools/galaxy-central/eggs/drmaa-0.4b3-py2.6.egg/drmaa/helper s.py", line 213, in c return f(*(args + (error_buffer, sizeof(error_buffer)))) File "/mnt/galaxyTools/galaxy-central/eggs/drmaa-0.4b3-py2.6.egg/drmaa/errors .py", line 90, in error_check raise _ERRORS[code-1]("code %s: %s" % (code, error_buffer.value)) DeniedByDrmException: code 17: error: no suitable queues 148.177.129.210 - - [15/Feb/2012:11:30:56 +0000] "POST /root/history_item_updates HTTP/1.0" 200 - "http://ec2-23-20-77-195.compute-1.amazonaws.com/history" "Mozilla/5.0 (Windows NT 5.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1" galaxy.web.framework DEBUG 2012-02-15 11:30:59,815 Error: this request returned None from get_history(): http://127.0.0.1:8080/ 127.0.0.1 - - [15/Feb/2012:11:30:59 +0000] "GET / HTTP/1.1" 200 - "-" "Python-urllib/2.6" 148.177.129.210 - - [15/Feb/2012:11:31:00 +0000] "POST /root/history_item_updates HTTP/1.0" 200 - "http://ec2-23-20-77-195.compute-1.amazonaws.com/history" "Mozilla/5.0 (Windows NT 5.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1" 148.177.129.210 - - [15/Feb/2012:11:31:04 +0000] "POST /root/history_item_updates HTTP/1.0" 200 - "http://ec2-23-20-77-195.compute-1.amazonaws.com/history" "Mozilla/5.0 (Windows NT 5.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1" 148.177.129.210 - - [15/Feb/2012:11:31:08 +0000] "POST /root/history_item_updates HTTP/1.0" 200 - "http://ec2-23-20-77-195.compute-1.amazonaws.com/history" "Mozilla/5.0 (Windows NT 5.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1" 148.177.129.210 - - [15/Feb/2012:11:31:12 +0000] "POST /root/history_item_updates HTTP/1.0" 200 - "http://ec2-23-20-77-195.compute-1.amazonaws.com/history" "Mozilla/5.0 (Windows NT 5.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1" 148.177.129.210 - - [15/Feb/2012:11:31:17 +0000] "POST /root/history_item_updates HTTP/1.0" 200 - "http://ec2-23-20-77-195.compute-1.amazonaws.com/history" "Mozilla/5.0 (Windows NT 5.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1" galaxy.web.framework DEBUG 2012-02-15 11:31:19,186 Error: this request returned None from get_history(): http://127.0.0.1:8080/ 127.0.0.1 - - [15/Feb/2012:11:31:19 +0000] "GET / HTTP/1.1" 200 - "-" "Python-urllib/2.6" 148.177.129.210 - - [15/Feb/2012:11:31:21 +0000] "POST /root/history_item_updates HTTP/1.0" 200 - "http://ec2-23-20-77-195.compute-1.amazonaws.com/history" "Mozilla/5.0 (Windows NT 5.1; rv:10.0.1) Gecko/20100101 Firefox/10.0.1" Kind Regards Yves -----Original Message----- From: Brad Chapman [mailto:chapmanb@50mail.com] Sent: Wednesday, 15 February 2012 02:22 To: Wetzels, Yves [JRDBE Extern]; galaxy-dev@lists.bx.psu.edu Subject: Re: [galaxy-dev] Galaxy Cloudman - How to analyse > 1TB data ? Yves;
I am currently investigating if Galaxy Cloudman can help us in analyzing
large NGS datasets.
I was first impressed by the simple setup, the autoscaling and
useability of Galaxy Cloudman but soon ran into the EBS limit of 1 TB L
I thought to be clever and umounted the /mnt/galaxyData EBS volume,
created a logical volume of 2 TB and remounted this volume to
/mnt/galaxyData.
How did you create this volume? I know there are some tricks to get around the 1Tb limit: http://alestic.com/2009/06/ec2-ebs-raid In the screenshot you sent it looks like Cloudman is a bit confused about the disk size. The Disk Status lists 1.2Tb out of 668Gb, which might be the source of your problems.
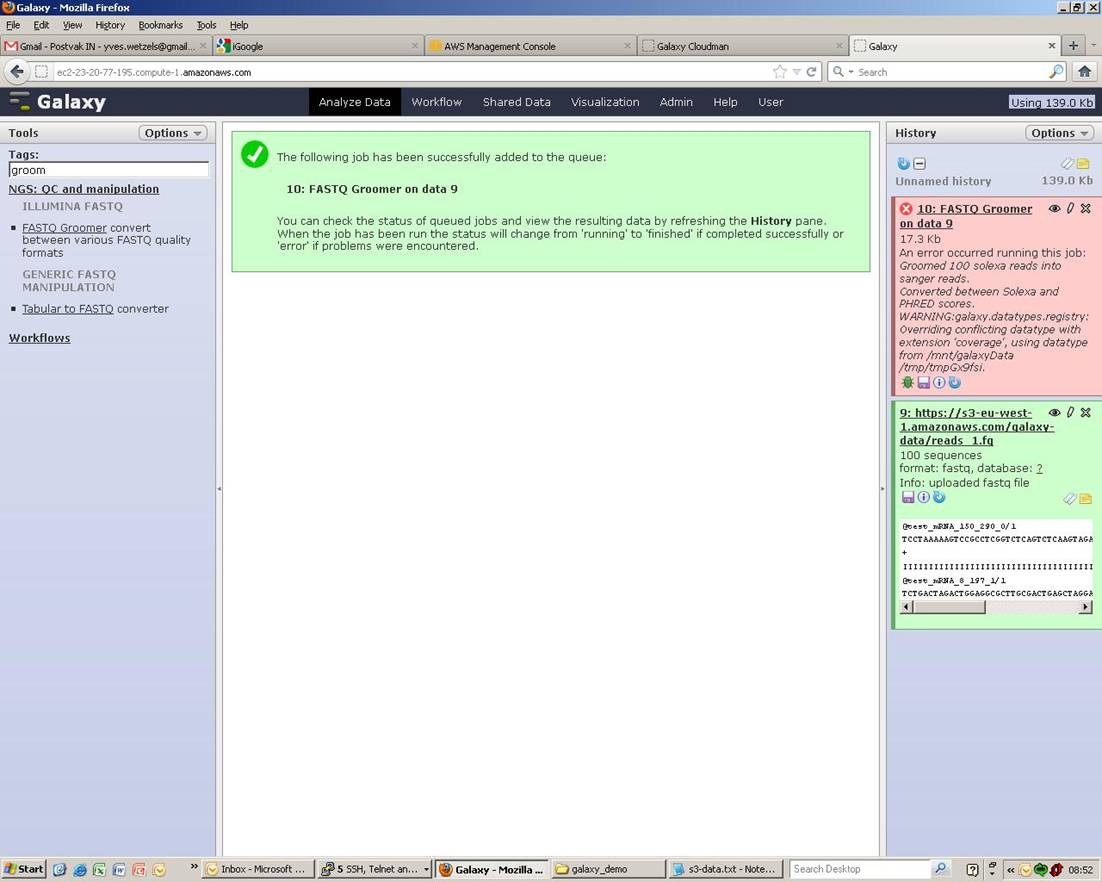
All is green as you can see from the picture below but running a tool is
not possible since Galaxy is not configured to work with logical volume
I assume.
Can you describe what errors you are seeing?
It is truly a waste having this fine setup (autoscaling) but this is not
useable if there is not enough storage ?
Does anybody has experience with this ? Tips, tricks ...
The more general answer is that folks do not normally use EBS this way since having large permanent EBS filesystems is expensive. S3 stores larger data, up to 50Tb, at a more reasonable price. S3 files are then copied to a transient EBS store, processed, and uploaded back to S3. This isn't as automated since it will be highly dependent on your workflow and what files you want to save, but might be worth exploring in general when using EC2. Hope this helps, Brad
{kind=link}
{kind=link}