
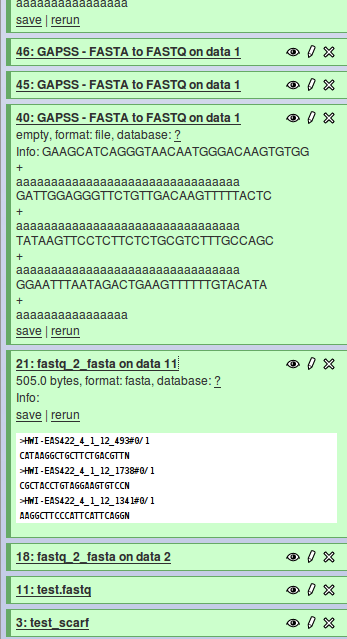
Hi, I recently started with galaxy, I got the : Galaxy build: $Rev 1733:a4214de3752e$ Now I need to add my own perl scipts to galaxy. This all goes fine, but there are some problems with the galaxy output look at the attachment: job 21 has an output in the white field, unlike job 40, I just can't seem to find out why? here are the xml's #######21############# <tool id="fast q 2 fasta " name="fastq_2_fasta"> <description>for each sequence in a file</description> <command interpreter="perl">fq2fa.pl $input $output</command> <inputs> <param format="fastq" name="input" type="data" label="Source file"/> </inputs> <outputs> <data format="fasta" name="output" /> </outputs> <tests> <test> <param name="input" value="fa_gc_content_input.fa"/> <output name="out_file1" file="fa_gc_content_output.txt"/> </test> </tests> <help> This tool computes GC content from a FASTA file. </help> </tool> ############################# ###########40################ <tool id="GAPSS_FASTA_to_FASTQ" name="GAPSS - FASTA to FASTQ"> <description>converter</description> <command interpreter="perl">GAPSS_FASTA2FASTQ.v2.pl $input $score $output</command> <inputs> <param format="fasta" name="input" type="data" label="FASTA File to convert" /> <param name="score" type="text" value="a" label="score" help="Use a if unsure." /> </inputs> <outputs> <data name="output" format="fastq" type="data" /> </outputs> <help> **What it does** This tool converts data from FASTQ format to FASTA format. #run as: perl GAPSS_FASTA2FASTQ.pl "FASTA file" "score to use or blank" #this script converts a FASTA file over to FASTQ #quality scores are by default Sanger, but can be adjusted #notes for user: # best sanger score = # best Solexa score = #input: FASTA file, and quality score to use #output: FASTQ file This tool is based on `GAPSS` by Matt and Michiel. http://www.lgtc.nl/GAPSS/ </help> </tool> ################ The perl script That needs to be added is for job 40 and looks like: ########PERl script job 40 ########### #!/usr/bin/perl #run as: perl GAPSS_FASTA2FASTQ.pl "FASTA file" "score to use or blank" #this script converts a FASTA file over to FASTQ #quality scores are by default Sanger, but can be adjusted #notes for user: # best sanger score = # best Solexa score = #input: FASTA file, and quality score to use #output: FASTQ file my $file_to_convert = $ARGV[0]; my $fastq_output_file_name = $file_to_convert.".fastq"; my $value_for_quality_score = $ARGV[1]; #set QC value to Sanger best () if no value given $value_for_quality_score =~ s/\n//; if ($value_for_quality_score eq ""){ $value_for_quality_score="a"; } #check is fasta format my $line1to4_fasta = `head -n 4 $file_to_convert`; my @array_line1to4_fasta=split(/\n/,$line1to4_fasta); if ( (@array_line1to4_fasta[0]=~/^>/) && (@array_line1to4_fasta[1]=~/[TAGCtagcNn]*/) && (@array_line1to4_fasta[2]=~/^>/) && (@array_line1to4_fasta[3]=~/[TAGCtagcNn]*/) ){}else{die "$file_to_convert is not a proper fasta file, terminated analysis\n";} #open file, open outfile, convert and print output, close infile, close outfile open(fasta_file,$file_to_convert)||die "could not open fasta file $file_to_convert\n"; open(fastq_file,">$fastq_output_file_name")||die "could not open fastq file $fastq_output_file_name to print to\n"; while (<fasta_file>){ chop; $_ =~ s/\n//; if ($_ =~ /^>/){ $_ =~ s/^>/@/;print fastq_file "$_\n"; }else{ print fastq_file "$_\n"; print fastq_file "+\n"; my $quality_line = $_; $quality_line =~ s/[TAGCtagcNn]/$value_for_quality_score/g; print fastq_file "$quality_line\n"; } } close (fasta_file)||die "could not close fasta file $file_to_convert \n"; close (fastq_file)||die "could not close fastq file $fastq_output_file_name\n"; ############################################ It just reformats a file and writes direct a file with .fastq behind it. I know there are other tools in galaxy but I just want mine to be put in and I just cant seem to get it to work. Can you give me some advise on the input and output parameters and how I control the white screen in galaxy, I just want the file that is written to be accessed by galaxy not the data displayed in the white screen, it will be for next generation sequencing and there wille be lots of fastq lines there. Thanks in advance. //Michel Villerius Human and Clinical Genetics Leiden University Medical Center
{kind=link}