Re: [galaxy-dev] rename output dataset in workflow - input dataset variable

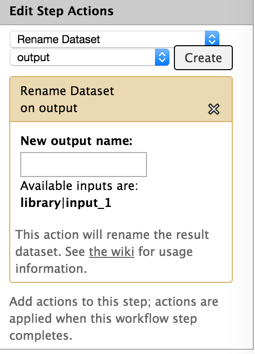
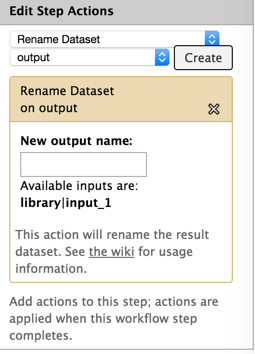
Hi Jan: Are you using input dataset tool? I'm not sure it's required - but I habitually use it. I'm attaching an image of a working renaming setup. I hope it helps. brad [cid:8ee56035-e56a-407f-8e02-1d29ef8a6279] ________________________________ From: Jan Hapala <jan@hapala.cz> Sent: Wednesday, November 12, 2014 9:29 AM To: Langhorst, Brad Subject: Re: [galaxy-dev] rename output dataset in workflow - input dataset variable Thanks, Brad. This is informative, but I'm still stuck. I have an input dataset which passes data to FASTQ Summary Statistics. (I have tried other tools, as well.) The output file name is: stats on: #{input1} The name of the Input dataset is: input1 I get this result: stats on: Jan 2014-11-12 14:06 GMT+01:00 Langhorst, Brad <Langhorst@neb.com<mailto:Langhorst@neb.com>>: For what it's worth (not much ;), I think the dataset naming is the single least intuitive part of the galaxy system for biologists. I think there's a proposal to "fix" this problem - and mainain the connection between input data set and derived data, but It doesn't seem to have gone anywhere yet. Anyway, you have to check the name of the field for each tool - it's sometimes "input" and sometimes something else. You want to use the #{} for naming. The ${} stuff is for parameters I also do this kind of thing: to keep the names from getting too long. #{input_1 | basename}.bam The basename removes everything after the last . character. Brad ________________________________ From: galaxy-dev-bounces@lists.bx.psu.edu<mailto:galaxy-dev-bounces@lists.bx.psu.edu> <galaxy-dev-bounces@lists.bx.psu.edu<mailto:galaxy-dev-bounces@lists.bx.psu.edu>> on behalf of Jan Hapala <jan@hapala.cz<mailto:jan@hapala.cz>> Sent: Wednesday, November 12, 2014 7:49 AM To: galaxy-dev Subject: [galaxy-dev] rename output dataset in workflow - input dataset variable Hello, I want to rename ouput datasets in a workflow in such a way that the name contains the name of the input dataset. I could not find instructions in the manual (and this info is missing in the Workflow editor - would be really helpful there!). I tried #{input}, e.g. "stats on: #{input}" (with no quotes), but I keep getting just "stats on:" The variable is empty. When I use ${input}, I get a variable field in the workflow form (I do not want this). My G. instance: Galaxy changeset: d1e1beeb532239250396dd8fbdc0156508c6744e<https://bitbucket.org/galaxy/galaxy-central/commits/d1e1beeb532239250396dd8fbdc0156508c6744e> Can anyone help me, please? Jan
{kind=link}

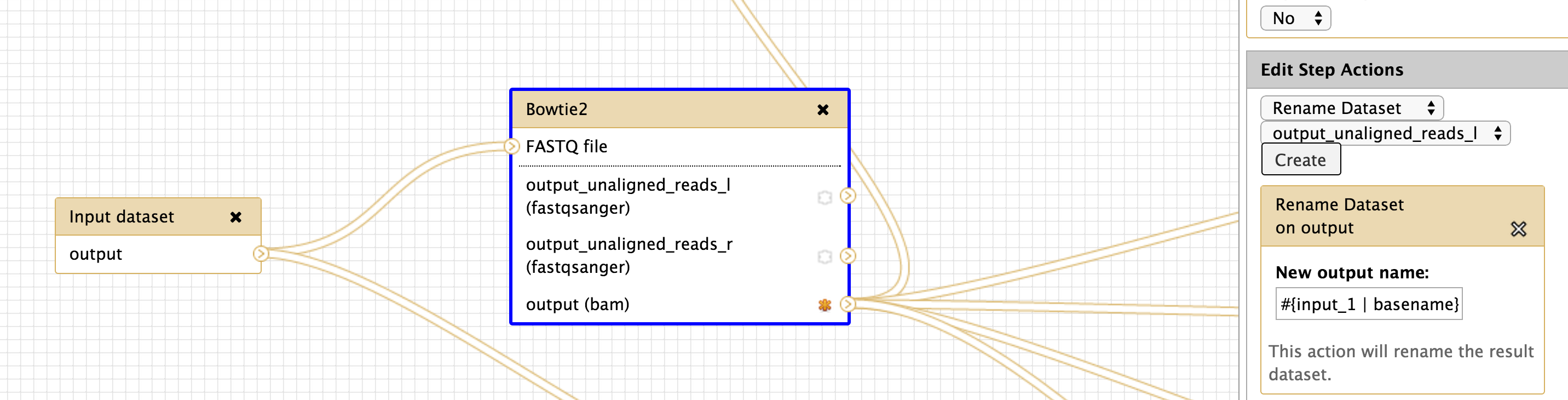
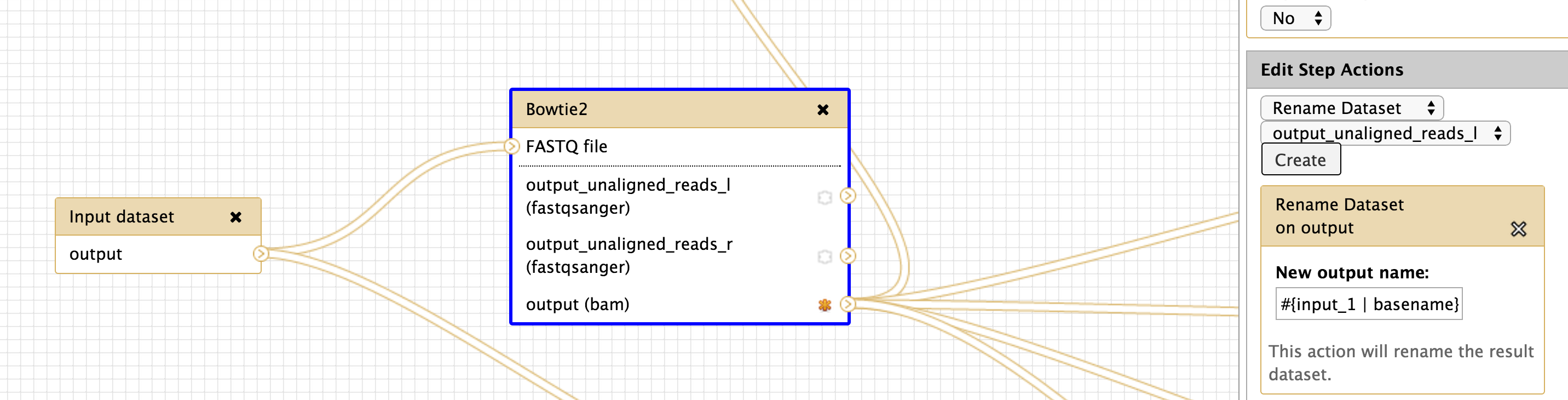
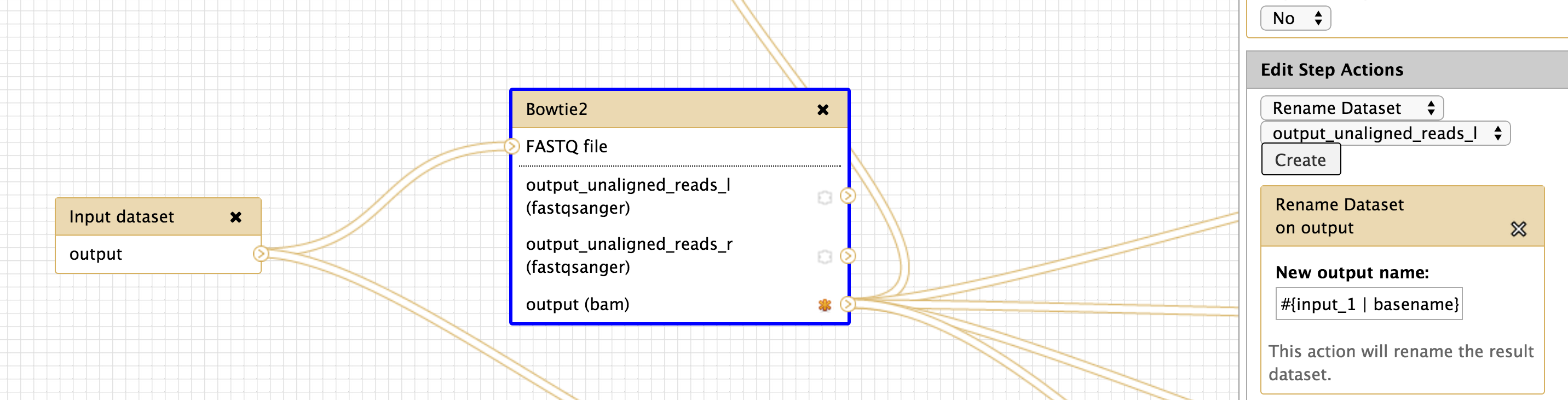
Hi all, For these parameters, 'input' refers to the exact tool input name. Recent versions of Galaxy will now tell you what the options are to use, like the following I see for bowtie2: [image: Inline image 1] I definitely agree that it's not intuitive, and I'm trying to think of ways to make this better -- suggestions definitely welcome. -Dannon On Wed, Nov 12, 2014 at 6:54 AM, Langhorst, Brad <Langhorst@neb.com> wrote:
Hi Jan:
Are you using input dataset tool? I'm not sure it's required - but I habitually use it.
I'm attaching an image of a working renaming setup. I hope it helps.
brad
------------------------------ *From:* Jan Hapala <jan@hapala.cz> *Sent:* Wednesday, November 12, 2014 9:29 AM *To:* Langhorst, Brad *Subject:* Re: [galaxy-dev] rename output dataset in workflow - input dataset variable
Thanks, Brad. This is informative, but I'm still stuck.
I have an input dataset which passes data to FASTQ Summary Statistics. (I have tried other tools, as well.) The output file name is: stats on: #{input1}
The name of the Input dataset is: input1
I get this result: stats on:
Jan
2014-11-12 14:06 GMT+01:00 Langhorst, Brad <Langhorst@neb.com>:
For what it's worth (not much ;), I think the dataset naming is the
single least intuitive part of the galaxy system for biologists.
I think there's a proposal to "fix" this problem - and mainain the connection between input data set and derived data, but It doesn't seem to have gone anywhere yet.
Anyway, you have to check the name of the field for each tool - it's sometimes "input" and sometimes something else.
You want to use the #{} for naming. The ${} stuff is for parameters
I also do this kind of thing: to keep the names from getting too long.
#{input_1 | basename}.bam
The basename removes everything after the last . character.
Brad
------------------------------ *From:* galaxy-dev-bounces@lists.bx.psu.edu < galaxy-dev-bounces@lists.bx.psu.edu> on behalf of Jan Hapala < jan@hapala.cz> *Sent:* Wednesday, November 12, 2014 7:49 AM *To:* galaxy-dev *Subject:* [galaxy-dev] rename output dataset in workflow - input dataset variable
Hello,
I want to rename ouput datasets in a workflow in such a way that the name contains the name of the input dataset. I could not find instructions in the manual (and this info is missing in the Workflow editor - would be really helpful there!).
I tried #{input}, e.g. "stats on: #{input}" (with no quotes), but I keep getting just "stats on:" The variable is empty. When I use ${input}, I get a variable field in the workflow form (I do not want this).
My G. instance: Galaxy changeset: d1e1beeb532239250396dd8fbdc0156508c6744e <https://bitbucket.org/galaxy/galaxy-central/commits/d1e1beeb532239250396dd8fbdc0156508c6744e>
Can anyone help me, please? Jan
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
{kind=link}
{kind=link}
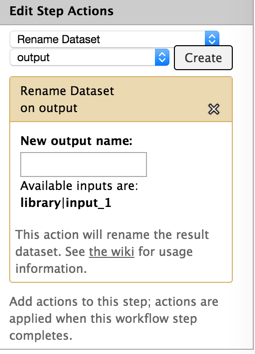
I think adding the available inputs is a good improvement - I know it will save me some mistakes. I think I might have been unclear in my comment ("single least intuitive part")... I'm not referring to how input name chaining works - I'm talking about the default naming of datasets based on the analysis step and the immediate inputs. When interpreting results, we care about two things: 1) which analysis 2) which sample is being described by that analysis. The chain of analysis is important, but its easily determined by looking at the info tab, or generating a workflow from the history to the order of events. The current naming system requires that we walk the entire chain of analysis back to the original dataset, or laboriously build every workflow to manually carry the sample information along in the input and output naming. If the default display convention showed the original dataset dataset name, much of that toting of input name could be avoided. Maybe I'll find some time to implement this someday... Brad ________________________________ From: Dannon Baker <dannon.baker@gmail.com> Sent: Thursday, November 13, 2014 10:05 AM To: Langhorst, Brad Cc: Jan Hapala; galaxy-dev@lists.bx.psu.edu Subject: Re: [galaxy-dev] rename output dataset in workflow - input dataset variable Hi all, For these parameters, 'input' refers to the exact tool input name. Recent versions of Galaxy will now tell you what the options are to use, like the following I see for bowtie2: [Inline image 1] I definitely agree that it's not intuitive, and I'm trying to think of ways to make this better -- suggestions definitely welcome. -Dannon On Wed, Nov 12, 2014 at 6:54 AM, Langhorst, Brad <Langhorst@neb.com<mailto:Langhorst@neb.com>> wrote: Hi Jan: Are you using input dataset tool? I'm not sure it's required - but I habitually use it. I'm attaching an image of a working renaming setup. I hope it helps. brad [cid:8ee56035-e56a-407f-8e02-1d29ef8a6279] ________________________________ From: Jan Hapala <jan@hapala.cz<mailto:jan@hapala.cz>> Sent: Wednesday, November 12, 2014 9:29 AM To: Langhorst, Brad Subject: Re: [galaxy-dev] rename output dataset in workflow - input dataset variable Thanks, Brad. This is informative, but I'm still stuck. I have an input dataset which passes data to FASTQ Summary Statistics. (I have tried other tools, as well.) The output file name is: stats on: #{input1} The name of the Input dataset is: input1 I get this result: stats on: Jan 2014-11-12 14:06 GMT+01:00 Langhorst, Brad <Langhorst@neb.com<mailto:Langhorst@neb.com>>: For what it's worth (not much ;), I think the dataset naming is the single least intuitive part of the galaxy system for biologists. I think there's a proposal to "fix" this problem - and mainain the connection between input data set and derived data, but It doesn't seem to have gone anywhere yet. Anyway, you have to check the name of the field for each tool - it's sometimes "input" and sometimes something else. You want to use the #{} for naming. The ${} stuff is for parameters I also do this kind of thing: to keep the names from getting too long. #{input_1 | basename}.bam The basename removes everything after the last . character. Brad ________________________________ From: galaxy-dev-bounces@lists.bx.psu.edu<mailto:galaxy-dev-bounces@lists.bx.psu.edu> <galaxy-dev-bounces@lists.bx.psu.edu<mailto:galaxy-dev-bounces@lists.bx.psu.edu>> on behalf of Jan Hapala <jan@hapala.cz<mailto:jan@hapala.cz>> Sent: Wednesday, November 12, 2014 7:49 AM To: galaxy-dev Subject: [galaxy-dev] rename output dataset in workflow - input dataset variable Hello, I want to rename ouput datasets in a workflow in such a way that the name contains the name of the input dataset. I could not find instructions in the manual (and this info is missing in the Workflow editor - would be really helpful there!). I tried #{input}, e.g. "stats on: #{input}" (with no quotes), but I keep getting just "stats on:" The variable is empty. When I use ${input}, I get a variable field in the workflow form (I do not want this). My G. instance: Galaxy changeset: d1e1beeb532239250396dd8fbdc0156508c6744e<https://bitbucket.org/galaxy/galaxy-central/commits/d1e1beeb532239250396dd8fbdc0156508c6744e> Can anyone help me, please? Jan ___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/ To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
{kind=link}
{kind=link}

Brad et al, I would like second the issue you raise so succinctly. The failure to automatically track the original sample name throughout the analysis (that and array selection of paired end reads) is one of the biggest barriers people face for doing work on many samples in galaxy. It just gets very confusing unless you spend a lot of time workarounds (creating workflows to rename things, editing datasets individually, etc) – especially for non-programmer users, for whom workflows with variables and API calls are beyond the pale. Regards, Curtis From: galaxy-dev-bounces@lists.bx.psu.edu [mailto:galaxy-dev-bounces@lists.bx.psu.edu] On Behalf Of Langhorst, Brad Sent: Thursday, November 13, 2014 3:23 PM To: Dannon Baker Cc: galaxy-dev@lists.bx.psu.edu Subject: Re: [galaxy-dev] rename output dataset in workflow - input dataset variable I think adding the available inputs is a good improvement - I know it will save me some mistakes. I think I might have been unclear in my comment ("single least intuitive part")... I'm not referring to how input name chaining works - I'm talking about the default naming of datasets based on the analysis step and the immediate inputs. When interpreting results, we care about two things: 1) which analysis 2) which sample is being described by that analysis. The chain of analysis is important, but its easily determined by looking at the info tab, or generating a workflow from the history to the order of events. The current naming system requires that we walk the entire chain of analysis back to the original dataset, or laboriously build every workflow to manually carry the sample information along in the input and output naming. If the default display convention showed the original dataset dataset name, much of that toting of input name could be avoided. Maybe I'll find some time to implement this someday... Brad ________________________________ From: Dannon Baker <dannon.baker@gmail.com<mailto:dannon.baker@gmail.com>> Sent: Thursday, November 13, 2014 10:05 AM To: Langhorst, Brad Cc: Jan Hapala; galaxy-dev@lists.bx.psu.edu<mailto:galaxy-dev@lists.bx.psu.edu> Subject: Re: [galaxy-dev] rename output dataset in workflow - input dataset variable Hi all, For these parameters, 'input' refers to the exact tool input name. Recent versions of Galaxy will now tell you what the options are to use, like the following I see for bowtie2: [Inline image 1] I definitely agree that it's not intuitive, and I'm trying to think of ways to make this better -- suggestions definitely welcome. -Dannon On Wed, Nov 12, 2014 at 6:54 AM, Langhorst, Brad <Langhorst@neb.com<mailto:Langhorst@neb.com>> wrote: Hi Jan: Are you using input dataset tool? I'm not sure it's required - but I habitually use it. I'm attaching an image of a working renaming setup. I hope it helps. brad [cid:image002.png@01D00405.AA7E35D0] ________________________________ From: Jan Hapala <jan@hapala.cz<mailto:jan@hapala.cz>> Sent: Wednesday, November 12, 2014 9:29 AM To: Langhorst, Brad Subject: Re: [galaxy-dev] rename output dataset in workflow - input dataset variable Thanks, Brad. This is informative, but I'm still stuck. I have an input dataset which passes data to FASTQ Summary Statistics. (I have tried other tools, as well.) The output file name is: stats on: #{input1} The name of the Input dataset is: input1 I get this result: stats on: Jan 2014-11-12 14:06 GMT+01:00 Langhorst, Brad <Langhorst@neb.com<mailto:Langhorst@neb.com>>: For what it's worth (not much ;), I think the dataset naming is the single least intuitive part of the galaxy system for biologists. I think there's a proposal to "fix" this problem - and mainain the connection between input data set and derived data, but It doesn't seem to have gone anywhere yet. Anyway, you have to check the name of the field for each tool - it's sometimes "input" and sometimes something else. You want to use the #{} for naming. The ${} stuff is for parameters I also do this kind of thing: to keep the names from getting too long. #{input_1 | basename}.bam The basename removes everything after the last . character. Brad ________________________________ From: galaxy-dev-bounces@lists.bx.psu.edu<mailto:galaxy-dev-bounces@lists.bx.psu.edu> <galaxy-dev-bounces@lists.bx.psu.edu<mailto:galaxy-dev-bounces@lists.bx.psu.edu>> on behalf of Jan Hapala <jan@hapala.cz<mailto:jan@hapala.cz>> Sent: Wednesday, November 12, 2014 7:49 AM To: galaxy-dev Subject: [galaxy-dev] rename output dataset in workflow - input dataset variable Hello, I want to rename ouput datasets in a workflow in such a way that the name contains the name of the input dataset. I could not find instructions in the manual (and this info is missing in the Workflow editor - would be really helpful there!). I tried #{input}, e.g. "stats on: #{input}" (with no quotes), but I keep getting just "stats on:" The variable is empty. When I use ${input}, I get a variable field in the workflow form (I do not want this). My G. instance: Galaxy changeset: d1e1beeb532239250396dd8fbdc0156508c6744e<https://bitbucket.org/galaxy/galaxy-central/commits/d1e1beeb532239250396dd8fbdc0156508c6744e> Can anyone help me, please? Jan ___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/ To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
{kind=link}
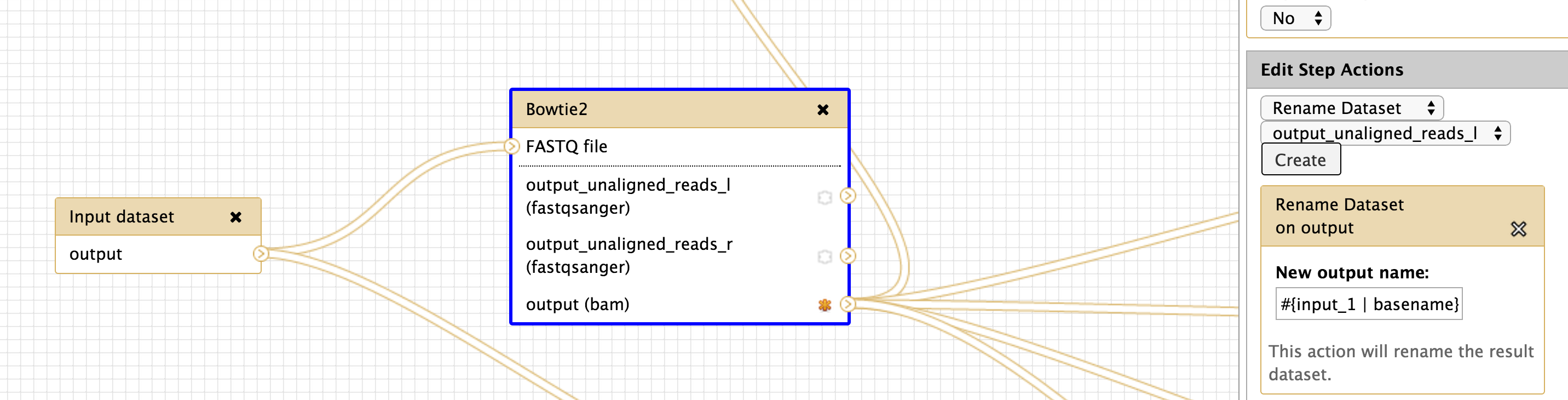{kind=link}

Yes :( There's been some past discussion of this from a tool developer perspective, e.g. https://trello.com/c/JnhOEqow and http://dev.list.galaxyproject.org/Using-input-dataset-names-in-output-datase... The best individual tool authors can do is something like "$input.name processed with XXX" or "XXX on $input.name" which in a long pipeline results in extremely long names with tools sometimes prefixed and sometimes postfixed. :( Of course, things get really complicated when a tool has multiple input files - in some cases the tool author could regard one set of files as primary and preserve their name/tag only, Naming things is hard. Peter On Wed, Nov 19, 2014 at 8:34 PM, Curtis Hendrickson (Campus) <curtish@uab.edu> wrote:
Brad et al,
I would like second the issue you raise so succinctly. The failure to automatically track the original sample name throughout the analysis (that and array selection of paired end reads) is one of the biggest barriers people face for doing work on many samples in galaxy. It just gets very confusing unless you spend a lot of time workarounds (creating workflows to rename things, editing datasets individually, etc) – especially for non-programmer users, for whom workflows with variables and API calls are beyond the pale.
Regards,
Curtis

All - Certainly this is a very real and important problem. The devteam hasn't moved on the tagging approach outlined in the dev thread referenced by Peter and I suspect that is because I the prevailing thought on the team is that dataset naming is not the most appropriate abstraction to use to address that (though personally I would be keen to merge a pull request for the compromise approach I outlined if someone wants to put it together). Outside the realm of dataset naming however - the devteam is actively working on this problem in at least two ways. - If one is performing an interactive analysis with a few initial inputs - showing the structure and connection between datasets in the history I suspect will be a more robust way to track connections and inputs throughout an analysis than dataset names. Carl has prototyped and demonstrated some stuff internally for showing such structures - I would assume it is coming in a future release. - If you have many samples - I suspect no approach based around individual datasets will be sufficient. Dataset collections however have been designed from the ground up with sample tracking in mind and I think with very little effort on the part of tool developers users get a very effective sample tracking. Dataset lists and lists of paired datasets (say representing replicates, samples, conditions, or patients, etc...) or more deeply nested data structures (representing hierarchical combinations of those things) are created with element identifiers at each level of the hierarchy that are preserved throughout a complex analysis transparently in a way that names are not - and with very little effort tool developers can leverage these at merging steps - to produce reports, etc.... (bit.ly/gcc2014workflows). I am not claiming the problem has been solved - but I did want to express that the devteam is working on it very actively and things will continue to improve in this realm. Thanks for the comments, -John On Fri, Nov 21, 2014 at 4:20 AM, Peter Cock <p.j.a.cock@googlemail.com> wrote:
Yes :(
There's been some past discussion of this from a tool developer perspective, e.g. https://trello.com/c/JnhOEqow and http://dev.list.galaxyproject.org/Using-input-dataset-names-in-output-datase...
The best individual tool authors can do is something like "$input.name processed with XXX" or "XXX on $input.name" which in a long pipeline results in extremely long names with tools sometimes prefixed and sometimes postfixed. :(
Of course, things get really complicated when a tool has multiple input files - in some cases the tool author could regard one set of files as primary and preserve their name/tag only,
Naming things is hard.
Peter
On Wed, Nov 19, 2014 at 8:34 PM, Curtis Hendrickson (Campus) <curtish@uab.edu> wrote:
Brad et al,
I would like second the issue you raise so succinctly. The failure to automatically track the original sample name throughout the analysis (that and array selection of paired end reads) is one of the biggest barriers people face for doing work on many samples in galaxy. It just gets very confusing unless you spend a lot of time workarounds (creating workflows to rename things, editing datasets individually, etc) – especially for non-programmer users, for whom workflows with variables and API calls are beyond the pale.
Regards,
Curtis
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: https://lists.galaxyproject.org/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
participants (5)
-
 Curtis Hendrickson (Campus)
Curtis Hendrickson (Campus) -
 Dannon Baker
Dannon Baker -
 John Chilton
John Chilton -
 Langhorst, Brad
Langhorst, Brad -
 Peter Cock
Peter Cock