Re: [galaxy-dev] Question regarding walltime exceeded not being correctly reported via the WebUI

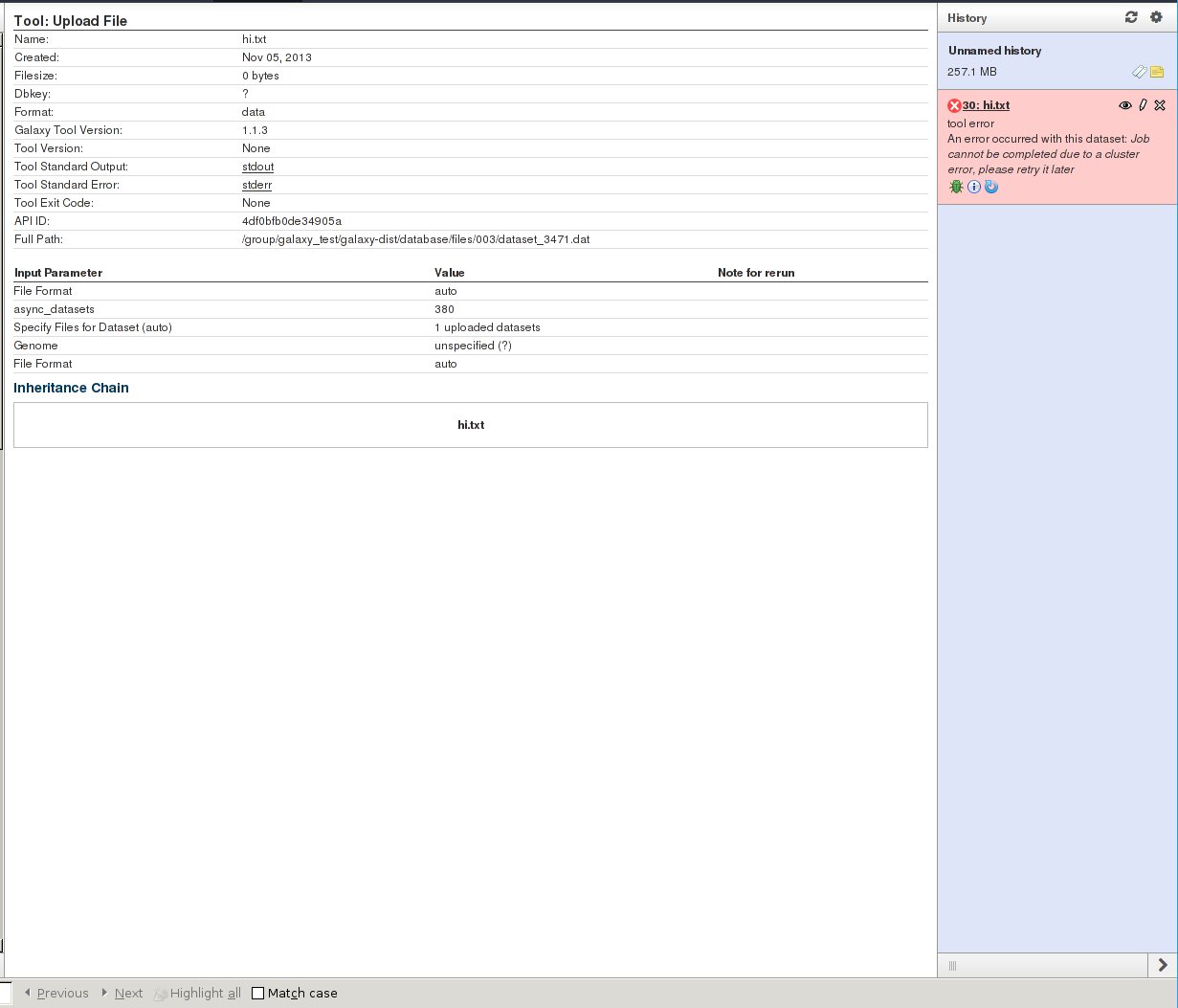
Hi, John, Thank you for taking the time to help me look into this issue. I have applied the patch you provided and confirmed that it appears to help remediate the problem (when a walltime is exceeded feedback is in fact provided via the Galaxy web UI; it no longer appears that jobs are running indefinitely). One thing I would like to note is that the error that is provided to the user is generic, i.e. the web UI reports "An error occurred with this dataset: Job cannot be completed due to a cluster error, please retry it later". So, the fact that a Walltime exceeded error actually occurred is not presented to the user (I am not sure if this is intentional or not). Again, I appreciate you taking the time to verify and patch this issue. I have attached a screenshot of the output for your review. I am probably going to be testing Galaxy with Torque 4.2.5 in the coming weeks, I will let you know if I identify any additional problems. Thank you so much have a wonderful day. Dan Sullivan On Tue, Nov 5, 2013 at 8:48 AM, John Chilton <chilton@msi.umn.edu> wrote:
Hey Daniel,
Thanks so much for the details problem report, it was very helpful. Reviewing the code there appears to be a bug in the PBS job runner - in some cases pbs_job_state.stop_job is never set but is attempted to be read. I don't have torque so I don't have a great test setup for this problem, any chance you can make the following changes for me and let me know if they work?
Between the following two lines:
log.error( '(%s/%s) PBS job failed: %s' % ( galaxy_job_id, job_id, JOB_EXIT_STATUS.get( int( status.exit_status ), 'Unknown error: %s' % status.exit_status ) ) ) self.work_queue.put( ( self.fail_job, pbs_job_state ) )
log.error( '(%s/%s) PBS job failed: %s' % ( galaxy_job_id, job_id, JOB_EXIT_STATUS.get( int( status.exit_status ), 'Unknown error: %s' % status.exit_status ) ) ) pbs_job_state.stop_job = False self.work_queue.put( ( self.fail_job, pbs_job_state ) )
And at the top of the file can you add a -11 option to the JOB_EXIT_STATUS to indicate a job timeout.
I have attached a patch that would apply against the latest stable - it will probably will work against your branch as well.
If you would rather not act as my QC layer, I can try to come up with a way to do some testing on my end :).
Thanks again, -John
On Mon, Nov 4, 2013 at 10:10 AM, Daniel Patrick Sullivan <dansullivan@gmail.com> wrote:
Hi, Galaxy Developers,
I have what I hops is somewhat of a basic question regarding Galaxy's interaction with a pbs job cluster and information reported via the webUI. Basically, in certain situations, the walltime of a specific job is exceeded. This is of course to be expected and all fine and understandeable.
My problem is that the information is not being relayed back to the end user via the Galaxy web UI, which causes confusion in our Galaxy user community. Basically the Torque scheduler generates the following message when a walltime is exceeded:
11/04/2013 08:39:45;000d;PBS_Server.30621;Job;163.sctest.cri.uchicago.edu;preparing to send 'a' mail for job 163.sctest.cri.uchicago.edu to s.cri.galaxy@crigalaxy-test.uchicago.edu (Job exceeded its walltime limit. Job was aborted 11/04/2013 08:39:45;0009;PBS_Server.30621;Job;163.sctest.cri.uchicago.edu;job exit status -11 handled
Now, my problem is that this status -11 return code is not being correctly handled by Galaxy. What happens is that Galaxy throws an exception, specificially:
10.135.217.178 - - [04/Nov/2013:08:39:42 -0500] "GET /api/histories/90240358ebde1489 HTTP/1.1" 200 - "https://crigalaxy-test.uchicago.edu/history" "Mozilla/5.0 (X11; Linux x86_64; rv:23.0) Gecko/20100101 Firefox/23.0" galaxy.jobs.runners.pbs DEBUG 2013-11-04 08:39:46,137 (2150/163.sctest.cri.uchicago.edu) PBS job state changed from R to C galaxy.jobs.runners.pbs ERROR 2013-11-04 08:39:46,139 (2150/163.sctest.cri.uchicago.edu) PBS job failed: Unknown error: -11 galaxy.jobs.runners ERROR 2013-11-04 08:39:46,139 (unknown) Unhandled exception calling fail_job Traceback (most recent call last): File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/__init__.py", line 60, in run_next method(arg) File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py", line 561, in fail_job if pbs_job_state.stop_job: AttributeError: 'AsynchronousJobState' object has no attribute 'stop_job'
After this exception occurs, the Galaxy job status via the Web UI is still reported as "Job is currently running". It appears that the job will remain in this state (from the end users perspective) indefinitely. Has anybody seen this issue before?
I noticed that return code -11 does not exist in /group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py under the JOB_EXIT_STATUS dictionary. I tried adding an entry for this, however when I do the exception changes to:
galaxy.jobs.runners.pbs ERROR 2013-11-04 10:02:17,274 (2151/164.sctest.cri.uchicago.edu) PBS job failed: job walltime exceeded galaxy.jobs.runners ERROR 2013-11-04 10:02:17,275 (unknown) Unhandled exception calling fail_job Traceback (most recent call last): File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/__init__.py", line 60, in run_next method(arg) File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py", line 562, in fail_job if pbs_job_state.stop_job: AttributeError: 'AsynchronousJobState' object has no attribute 'stop_job'
I am wondering if this is a bug or if it is just because I am using a newer version of TORQUE (I am using TORQUE 4.2.2).
In terms of Galaxy, I am using:
[s.cri.galaxy@crigalaxy-test galaxy-dist]$ hg parents changeset: 10408:6822f41bc9bb branch: stable parent: 10393:d05bf67aefa6 user: Dave Bouvier <dave@bx.psu.edu> date: Mon Aug 19 13:06:17 2013 -0400 summary: Fix for case where running functional tests might overwrite certain files in database/files.
[s.cri.galaxy@crigalaxy-test galaxy-dist]$
Does anybody know how I could fix this such that walltime exceeded messages are correctly reporeted via the Galaxy web UI for TORQUE 4.2.2? Thank you so much for your input and guidance, and for the ongoing development of Galaxy.
Dan Sullivan
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
{kind=link}

On Tue, Nov 5, 2013 at 11:53 AM, Daniel Patrick Sullivan <dansullivan@gmail.com> wrote:
Hi, John,
Thank you for taking the time to help me look into this issue. I have applied the patch you provided and confirmed that it appears to help remediate the problem (when a walltime is exceeded feedback is in fact provided via the Galaxy web UI; it no longer appears that jobs are running indefinitely). One thing I would like to note is that the error that is provided to the user is generic, i.e. the web UI reports "An error occurred with this dataset: Job cannot be completed due to a cluster error, please retry it later". So, the fact that a Walltime exceeded error actually occurred is not presented to the user (I am not sure if this is intentional or not). Again, I appreciate you taking the time to verify and patch this issue. I have attached a screenshot of the output for your review.
Glad we are making progress - I have committed that previous patch to galaxy-central. Lets see if we cannot improve the user feedback so they know they hit the maximum walltime. Can you try this new patch? The message about the timeout was being built but it was not being logged not set as the error message on the dataset - this should resolve that.
I am probably going to be testing Galaxy with Torque 4.2.5 in the coming weeks, I will let you know if I identify any additional problems. Thank you so much have a wonderful day.
You too, thanks for working with me on fixing this! -John
Dan Sullivan
On Tue, Nov 5, 2013 at 8:48 AM, John Chilton <chilton@msi.umn.edu> wrote:
Hey Daniel,
Thanks so much for the details problem report, it was very helpful. Reviewing the code there appears to be a bug in the PBS job runner - in some cases pbs_job_state.stop_job is never set but is attempted to be read. I don't have torque so I don't have a great test setup for this problem, any chance you can make the following changes for me and let me know if they work?
Between the following two lines:
log.error( '(%s/%s) PBS job failed: %s' % ( galaxy_job_id, job_id, JOB_EXIT_STATUS.get( int( status.exit_status ), 'Unknown error: %s' % status.exit_status ) ) ) self.work_queue.put( ( self.fail_job, pbs_job_state ) )
log.error( '(%s/%s) PBS job failed: %s' % ( galaxy_job_id, job_id, JOB_EXIT_STATUS.get( int( status.exit_status ), 'Unknown error: %s' % status.exit_status ) ) ) pbs_job_state.stop_job = False self.work_queue.put( ( self.fail_job, pbs_job_state ) )
And at the top of the file can you add a -11 option to the JOB_EXIT_STATUS to indicate a job timeout.
I have attached a patch that would apply against the latest stable - it will probably will work against your branch as well.
If you would rather not act as my QC layer, I can try to come up with a way to do some testing on my end :).
Thanks again, -John
On Mon, Nov 4, 2013 at 10:10 AM, Daniel Patrick Sullivan <dansullivan@gmail.com> wrote:
Hi, Galaxy Developers,
I have what I hops is somewhat of a basic question regarding Galaxy's interaction with a pbs job cluster and information reported via the webUI. Basically, in certain situations, the walltime of a specific job is exceeded. This is of course to be expected and all fine and understandeable.
My problem is that the information is not being relayed back to the end user via the Galaxy web UI, which causes confusion in our Galaxy user community. Basically the Torque scheduler generates the following message when a walltime is exceeded:
11/04/2013 08:39:45;000d;PBS_Server.30621;Job;163.sctest.cri.uchicago.edu;preparing to send 'a' mail for job 163.sctest.cri.uchicago.edu to s.cri.galaxy@crigalaxy-test.uchicago.edu (Job exceeded its walltime limit. Job was aborted 11/04/2013 08:39:45;0009;PBS_Server.30621;Job;163.sctest.cri.uchicago.edu;job exit status -11 handled
Now, my problem is that this status -11 return code is not being correctly handled by Galaxy. What happens is that Galaxy throws an exception, specificially:
10.135.217.178 - - [04/Nov/2013:08:39:42 -0500] "GET /api/histories/90240358ebde1489 HTTP/1.1" 200 - "https://crigalaxy-test.uchicago.edu/history" "Mozilla/5.0 (X11; Linux x86_64; rv:23.0) Gecko/20100101 Firefox/23.0" galaxy.jobs.runners.pbs DEBUG 2013-11-04 08:39:46,137 (2150/163.sctest.cri.uchicago.edu) PBS job state changed from R to C galaxy.jobs.runners.pbs ERROR 2013-11-04 08:39:46,139 (2150/163.sctest.cri.uchicago.edu) PBS job failed: Unknown error: -11 galaxy.jobs.runners ERROR 2013-11-04 08:39:46,139 (unknown) Unhandled exception calling fail_job Traceback (most recent call last): File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/__init__.py", line 60, in run_next method(arg) File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py", line 561, in fail_job if pbs_job_state.stop_job: AttributeError: 'AsynchronousJobState' object has no attribute 'stop_job'
After this exception occurs, the Galaxy job status via the Web UI is still reported as "Job is currently running". It appears that the job will remain in this state (from the end users perspective) indefinitely. Has anybody seen this issue before?
I noticed that return code -11 does not exist in /group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py under the JOB_EXIT_STATUS dictionary. I tried adding an entry for this, however when I do the exception changes to:
galaxy.jobs.runners.pbs ERROR 2013-11-04 10:02:17,274 (2151/164.sctest.cri.uchicago.edu) PBS job failed: job walltime exceeded galaxy.jobs.runners ERROR 2013-11-04 10:02:17,275 (unknown) Unhandled exception calling fail_job Traceback (most recent call last): File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/__init__.py", line 60, in run_next method(arg) File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py", line 562, in fail_job if pbs_job_state.stop_job: AttributeError: 'AsynchronousJobState' object has no attribute 'stop_job'
I am wondering if this is a bug or if it is just because I am using a newer version of TORQUE (I am using TORQUE 4.2.2).
In terms of Galaxy, I am using:
[s.cri.galaxy@crigalaxy-test galaxy-dist]$ hg parents changeset: 10408:6822f41bc9bb branch: stable parent: 10393:d05bf67aefa6 user: Dave Bouvier <dave@bx.psu.edu> date: Mon Aug 19 13:06:17 2013 -0400 summary: Fix for case where running functional tests might overwrite certain files in database/files.
[s.cri.galaxy@crigalaxy-test galaxy-dist]$
Does anybody know how I could fix this such that walltime exceeded messages are correctly reporeted via the Galaxy web UI for TORQUE 4.2.2? Thank you so much for your input and guidance, and for the ongoing development of Galaxy.
Dan Sullivan
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
Hi, John, Based on my initial testing the application of your patch 2 successfully conveys the job walltime exceeded error to the web UI. As far as I am concerned you resolved this issue perfectly. Thank you so much for your help with this. I will let you know if I experience any additional issues. Respectfully yours, Dan Sullivan On Tue, Nov 5, 2013 at 8:52 PM, John Chilton <chilton@msi.umn.edu> wrote:
On Tue, Nov 5, 2013 at 11:53 AM, Daniel Patrick Sullivan <dansullivan@gmail.com> wrote:
Hi, John,
Thank you for taking the time to help me look into this issue. I have applied the patch you provided and confirmed that it appears to help remediate the problem (when a walltime is exceeded feedback is in fact provided via the Galaxy web UI; it no longer appears that jobs are running indefinitely). One thing I would like to note is that the error that is provided to the user is generic, i.e. the web UI reports "An error occurred with this dataset: Job cannot be completed due to a cluster error, please retry it later". So, the fact that a Walltime exceeded error actually occurred is not presented to the user (I am not sure if this is intentional or not). Again, I appreciate you taking the time to verify and patch this issue. I have attached a screenshot of the output for your review.
Glad we are making progress - I have committed that previous patch to galaxy-central. Lets see if we cannot improve the user feedback so they know they hit the maximum walltime. Can you try this new patch? The message about the timeout was being built but it was not being logged not set as the error message on the dataset - this should resolve that.
I am probably going to be testing Galaxy with Torque 4.2.5 in the coming weeks, I will let you know if I identify any additional problems. Thank
you
so much have a wonderful day.
You too, thanks for working with me on fixing this!
-John
Dan Sullivan
On Tue, Nov 5, 2013 at 8:48 AM, John Chilton <chilton@msi.umn.edu>
wrote:
Hey Daniel,
Thanks so much for the details problem report, it was very helpful. Reviewing the code there appears to be a bug in the PBS job runner - in some cases pbs_job_state.stop_job is never set but is attempted to be read. I don't have torque so I don't have a great test setup for this problem, any chance you can make the following changes for me and let me know if they work?
Between the following two lines:
log.error( '(%s/%s) PBS job failed: %s' % ( galaxy_job_id, job_id, JOB_EXIT_STATUS.get( int( status.exit_status ), 'Unknown error: %s' % status.exit_status ) ) ) self.work_queue.put( ( self.fail_job, pbs_job_state
)
)
log.error( '(%s/%s) PBS job failed: %s' % ( galaxy_job_id, job_id, JOB_EXIT_STATUS.get( int( status.exit_status ), 'Unknown error: %s' % status.exit_status ) ) ) pbs_job_state.stop_job = False self.work_queue.put( ( self.fail_job, pbs_job_state ) )
And at the top of the file can you add a -11 option to the JOB_EXIT_STATUS to indicate a job timeout.
I have attached a patch that would apply against the latest stable - it will probably will work against your branch as well.
If you would rather not act as my QC layer, I can try to come up with a way to do some testing on my end :).
Thanks again, -John
On Mon, Nov 4, 2013 at 10:10 AM, Daniel Patrick Sullivan <dansullivan@gmail.com> wrote:
Hi, Galaxy Developers,
I have what I hops is somewhat of a basic question regarding Galaxy's interaction with a pbs job cluster and information reported via the webUI. Basically, in certain situations, the walltime of a specific job is exceeded. This is of course to be expected and all fine and understandeable.
My problem is that the information is not being relayed back to the end user via the Galaxy web UI, which causes confusion in our Galaxy user community. Basically the Torque scheduler generates the following message when a walltime is exceeded:
11/04/2013 08:39:45;000d;PBS_Server.30621;Job;163.sctest.cri.uchicago.edu ;preparing to send 'a' mail for job 163.sctest.cri.uchicago.edu to s.cri.galaxy@crigalaxy-test.uchicago.edu (Job exceeded its walltime limit. Job was aborted 11/04/2013 08:39:45;0009;PBS_Server.30621;Job;163.sctest.cri.uchicago.edu;job exit status -11 handled
Now, my problem is that this status -11 return code is not being correctly handled by Galaxy. What happens is that Galaxy throws an exception, specificially:
10.135.217.178 - - [04/Nov/2013:08:39:42 -0500] "GET /api/histories/90240358ebde1489 HTTP/1.1" 200 - "https://crigalaxy-test.uchicago.edu/history" "Mozilla/5.0 (X11; Linux x86_64; rv:23.0) Gecko/20100101 Firefox/23.0" galaxy.jobs.runners.pbs DEBUG 2013-11-04 08:39:46,137 (2150/163.sctest.cri.uchicago.edu) PBS job state changed from R to C galaxy.jobs.runners.pbs ERROR 2013-11-04 08:39:46,139 (2150/163.sctest.cri.uchicago.edu) PBS job failed: Unknown error: -11 galaxy.jobs.runners ERROR 2013-11-04 08:39:46,139 (unknown) Unhandled exception calling fail_job Traceback (most recent call last): File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/__init__.py", line 60, in run_next method(arg) File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py", line 561, in fail_job if pbs_job_state.stop_job: AttributeError: 'AsynchronousJobState' object has no attribute 'stop_job'
After this exception occurs, the Galaxy job status via the Web UI is still reported as "Job is currently running". It appears that the job will remain in this state (from the end users perspective) indefinitely. Has anybody seen this issue before?
I noticed that return code -11 does not exist in /group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py under the JOB_EXIT_STATUS dictionary. I tried adding an entry for this, however when I do the exception changes to:
galaxy.jobs.runners.pbs ERROR 2013-11-04 10:02:17,274 (2151/164.sctest.cri.uchicago.edu) PBS job failed: job walltime exceeded galaxy.jobs.runners ERROR 2013-11-04 10:02:17,275 (unknown) Unhandled exception calling fail_job Traceback (most recent call last): File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/__init__.py", line 60, in run_next method(arg) File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py", line 562, in fail_job if pbs_job_state.stop_job: AttributeError: 'AsynchronousJobState' object has no attribute 'stop_job'
I am wondering if this is a bug or if it is just because I am using a newer version of TORQUE (I am using TORQUE 4.2.2).
In terms of Galaxy, I am using:
[s.cri.galaxy@crigalaxy-test galaxy-dist]$ hg parents changeset: 10408:6822f41bc9bb branch: stable parent: 10393:d05bf67aefa6 user: Dave Bouvier <dave@bx.psu.edu> date: Mon Aug 19 13:06:17 2013 -0400 summary: Fix for case where running functional tests might overwrite certain files in database/files.
[s.cri.galaxy@crigalaxy-test galaxy-dist]$
Does anybody know how I could fix this such that walltime exceeded messages are correctly reporeted via the Galaxy web UI for TORQUE 4.2.2? Thank you so much for your input and guidance, and for the ongoing development of Galaxy.
Dan Sullivan
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
Hi, John, Actually, now that I am taking a look at this, I wanted to report something. I am actually not sure if this is a problem or not (based on what I can tell this is not causing any negative impact). The Galaxy log data is actually reporting that the cleanup failed (for my testing I am using the upload1 tool). galaxy.jobs.runners.pbs DEBUG 2013-11-06 16:04:05,150 (2156/ 169.sctest.cri.uchicago.edu) PBS job state changed from R to C galaxy.jobs.runners.pbs ERROR 2013-11-06 16:04:05,152 (2156/ 169.sctest.cri.uchicago.edu) PBS job failed: job maximum walltime exceeded galaxy.datatypes.metadata DEBUG 2013-11-06 16:04:05,389 Cleaning up external metadata files galaxy.datatypes.metadata DEBUG 2013-11-06 16:04:05,421 Failed to cleanup MetadataTempFile temp files from /group/galaxy_test/galaxy-dist/database/job_working_directory/002/2156/metadata_out_HistoryDatasetAssociation_381_8fH0ZU: No JSON object could be decoded: line 1 column 0 (char 0) galaxy.jobs.runners.pbs WARNING 2013-11-06 16:04:05,498 Unable to cleanup: [Errno 2] No such file or directory: '/group/galaxy_test/galaxy-dist/database/pbs/2156.ec' Like I said, as far as I can tell this isn't causing an problem (everything is being reported correctly via the web UI; this was my original problem and you definitely solved it). I figured it wouldn't hurt to report the message above regardless. Thank you again for all of your help. Respectfully yours, Dan Sullivan On Wed, Nov 6, 2013 at 4:10 PM, Daniel Patrick Sullivan < dansullivan@gmail.com> wrote:
Hi, John,
Based on my initial testing the application of your patch 2 successfully conveys the job walltime exceeded error to the web UI. As far as I am concerned you resolved this issue perfectly. Thank you so much for your help with this. I will let you know if I experience any additional issues.
Respectfully yours,
Dan Sullivan
On Tue, Nov 5, 2013 at 8:52 PM, John Chilton <chilton@msi.umn.edu> wrote:
On Tue, Nov 5, 2013 at 11:53 AM, Daniel Patrick Sullivan <dansullivan@gmail.com> wrote:
Hi, John,
Thank you for taking the time to help me look into this issue. I have applied the patch you provided and confirmed that it appears to help remediate the problem (when a walltime is exceeded feedback is in fact provided via the Galaxy web UI; it no longer appears that jobs are running indefinitely). One thing I would like to note is that the error that is provided to the user is generic, i.e. the web UI reports "An error occurred with this dataset: Job cannot be completed due to a cluster error, please retry it later". So, the fact that a Walltime exceeded error actually occurred is not presented to the user (I am not sure if this is intentional or not). Again, I appreciate you taking the time to verify and patch this issue. I have attached a screenshot of the output for your review.
Glad we are making progress - I have committed that previous patch to galaxy-central. Lets see if we cannot improve the user feedback so they know they hit the maximum walltime. Can you try this new patch? The message about the timeout was being built but it was not being logged not set as the error message on the dataset - this should resolve that.
I am probably going to be testing Galaxy with Torque 4.2.5 in the coming weeks, I will let you know if I identify any additional problems.
Thank you
so much have a wonderful day.
You too, thanks for working with me on fixing this!
-John
Dan Sullivan
On Tue, Nov 5, 2013 at 8:48 AM, John Chilton <chilton@msi.umn.edu>
wrote:
Hey Daniel,
Thanks so much for the details problem report, it was very helpful. Reviewing the code there appears to be a bug in the PBS job runner - in some cases pbs_job_state.stop_job is never set but is attempted to be read. I don't have torque so I don't have a great test setup for this problem, any chance you can make the following changes for me and let me know if they work?
Between the following two lines:
log.error( '(%s/%s) PBS job failed: %s' % ( galaxy_job_id, job_id, JOB_EXIT_STATUS.get( int( status.exit_status ), 'Unknown error: %s' % status.exit_status ) ) ) self.work_queue.put( ( self.fail_job,
pbs_job_state )
)
log.error( '(%s/%s) PBS job failed: %s' % ( galaxy_job_id, job_id, JOB_EXIT_STATUS.get( int( status.exit_status ), 'Unknown error: %s' % status.exit_status ) ) ) pbs_job_state.stop_job = False self.work_queue.put( ( self.fail_job, pbs_job_state ) )
And at the top of the file can you add a -11 option to the JOB_EXIT_STATUS to indicate a job timeout.
I have attached a patch that would apply against the latest stable - it will probably will work against your branch as well.
If you would rather not act as my QC layer, I can try to come up with a way to do some testing on my end :).
Thanks again, -John
On Mon, Nov 4, 2013 at 10:10 AM, Daniel Patrick Sullivan <dansullivan@gmail.com> wrote:
Hi, Galaxy Developers,
I have what I hops is somewhat of a basic question regarding Galaxy's interaction with a pbs job cluster and information reported via the webUI. Basically, in certain situations, the walltime of a specific job is exceeded. This is of course to be expected and all fine and understandeable.
My problem is that the information is not being relayed back to the end user via the Galaxy web UI, which causes confusion in our Galaxy user community. Basically the Torque scheduler generates the following message when a walltime is exceeded:
11/04/2013 08:39:45;000d;PBS_Server.30621;Job;163.sctest.cri.uchicago.edu ;preparing to send 'a' mail for job 163.sctest.cri.uchicago.edu to s.cri.galaxy@crigalaxy-test.uchicago.edu (Job exceeded its walltime limit. Job was aborted 11/04/2013 08:39:45;0009;PBS_Server.30621;Job;163.sctest.cri.uchicago.edu;job exit status -11 handled
Now, my problem is that this status -11 return code is not being correctly handled by Galaxy. What happens is that Galaxy throws an exception, specificially:
10.135.217.178 - - [04/Nov/2013:08:39:42 -0500] "GET /api/histories/90240358ebde1489 HTTP/1.1" 200 - "https://crigalaxy-test.uchicago.edu/history" "Mozilla/5.0 (X11; Linux x86_64; rv:23.0) Gecko/20100101 Firefox/23.0" galaxy.jobs.runners.pbs DEBUG 2013-11-04 08:39:46,137 (2150/163.sctest.cri.uchicago.edu) PBS job state changed from R to C galaxy.jobs.runners.pbs ERROR 2013-11-04 08:39:46,139 (2150/163.sctest.cri.uchicago.edu) PBS job failed: Unknown error: -11 galaxy.jobs.runners ERROR 2013-11-04 08:39:46,139 (unknown) Unhandled exception calling fail_job Traceback (most recent call last): File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/__init__.py", line 60, in run_next method(arg) File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py", line 561, in fail_job if pbs_job_state.stop_job: AttributeError: 'AsynchronousJobState' object has no attribute 'stop_job'
After this exception occurs, the Galaxy job status via the Web UI is still reported as "Job is currently running". It appears that the job will remain in this state (from the end users perspective) indefinitely. Has anybody seen this issue before?
I noticed that return code -11 does not exist in /group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py under the JOB_EXIT_STATUS dictionary. I tried adding an entry for this, however when I do the exception changes to:
galaxy.jobs.runners.pbs ERROR 2013-11-04 10:02:17,274 (2151/164.sctest.cri.uchicago.edu) PBS job failed: job walltime exceeded galaxy.jobs.runners ERROR 2013-11-04 10:02:17,275 (unknown) Unhandled exception calling fail_job Traceback (most recent call last): File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/__init__.py", line 60, in run_next method(arg) File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py", line 562, in fail_job if pbs_job_state.stop_job: AttributeError: 'AsynchronousJobState' object has no attribute 'stop_job'
I am wondering if this is a bug or if it is just because I am using a newer version of TORQUE (I am using TORQUE 4.2.2).
In terms of Galaxy, I am using:
[s.cri.galaxy@crigalaxy-test galaxy-dist]$ hg parents changeset: 10408:6822f41bc9bb branch: stable parent: 10393:d05bf67aefa6 user: Dave Bouvier <dave@bx.psu.edu> date: Mon Aug 19 13:06:17 2013 -0400 summary: Fix for case where running functional tests might overwrite certain files in database/files.
[s.cri.galaxy@crigalaxy-test galaxy-dist]$
Does anybody know how I could fix this such that walltime exceeded messages are correctly reporeted via the Galaxy web UI for TORQUE 4.2.2? Thank you so much for your input and guidance, and for the ongoing development of Galaxy.
Dan Sullivan
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
Thanks for the feedback, I have incorporated that previous patch into galaxy-central. As for the new warning message - I think this is fine. It is not surprising the process doesn't have an exit code - the job script itself never got to the point where that would have been written. If there are no observable problems, I wouldn't worry. http://stackoverflow.com/questions/234075/what-is-your-best-programmer-joke/... Thanks again, -John On Wed, Nov 6, 2013 at 4:32 PM, Daniel Patrick Sullivan <dansullivan@gmail.com> wrote:
Hi, John,
Actually, now that I am taking a look at this, I wanted to report something. I am actually not sure if this is a problem or not (based on what I can tell this is not causing any negative impact). The Galaxy log data is actually reporting that the cleanup failed (for my testing I am using the upload1 tool).
galaxy.jobs.runners.pbs DEBUG 2013-11-06 16:04:05,150 (2156/169.sctest.cri.uchicago.edu) PBS job state changed from R to C galaxy.jobs.runners.pbs ERROR 2013-11-06 16:04:05,152 (2156/169.sctest.cri.uchicago.edu) PBS job failed: job maximum walltime exceeded galaxy.datatypes.metadata DEBUG 2013-11-06 16:04:05,389 Cleaning up external metadata files galaxy.datatypes.metadata DEBUG 2013-11-06 16:04:05,421 Failed to cleanup MetadataTempFile temp files from /group/galaxy_test/galaxy-dist/database/job_working_directory/002/2156/metadata_out_HistoryDatasetAssociation_381_8fH0ZU: No JSON object could be decoded: line 1 column 0 (char 0) galaxy.jobs.runners.pbs WARNING 2013-11-06 16:04:05,498 Unable to cleanup: [Errno 2] No such file or directory: '/group/galaxy_test/galaxy-dist/database/pbs/2156.ec'
Like I said, as far as I can tell this isn't causing an problem (everything is being reported correctly via the web UI; this was my original problem and you definitely solved it). I figured it wouldn't hurt to report the message above regardless. Thank you again for all of your help.
Respectfully yours,
Dan Sullivan
On Wed, Nov 6, 2013 at 4:10 PM, Daniel Patrick Sullivan <dansullivan@gmail.com> wrote:
Hi, John,
Based on my initial testing the application of your patch 2 successfully conveys the job walltime exceeded error to the web UI. As far as I am concerned you resolved this issue perfectly. Thank you so much for your help with this. I will let you know if I experience any additional issues.
Respectfully yours,
Dan Sullivan
On Tue, Nov 5, 2013 at 8:52 PM, John Chilton <chilton@msi.umn.edu> wrote:
On Tue, Nov 5, 2013 at 11:53 AM, Daniel Patrick Sullivan <dansullivan@gmail.com> wrote:
Hi, John,
Thank you for taking the time to help me look into this issue. I have applied the patch you provided and confirmed that it appears to help remediate the problem (when a walltime is exceeded feedback is in fact provided via the Galaxy web UI; it no longer appears that jobs are running indefinitely). One thing I would like to note is that the error that is provided to the user is generic, i.e. the web UI reports "An error occurred with this dataset: Job cannot be completed due to a cluster error, please retry it later". So, the fact that a Walltime exceeded error actually occurred is not presented to the user (I am not sure if this is intentional or not). Again, I appreciate you taking the time to verify and patch this issue. I have attached a screenshot of the output for your review.
Glad we are making progress - I have committed that previous patch to galaxy-central. Lets see if we cannot improve the user feedback so they know they hit the maximum walltime. Can you try this new patch? The message about the timeout was being built but it was not being logged not set as the error message on the dataset - this should resolve that.
I am probably going to be testing Galaxy with Torque 4.2.5 in the coming weeks, I will let you know if I identify any additional problems. Thank you so much have a wonderful day.
You too, thanks for working with me on fixing this!
-John
Dan Sullivan
On Tue, Nov 5, 2013 at 8:48 AM, John Chilton <chilton@msi.umn.edu> wrote:
Hey Daniel,
Thanks so much for the details problem report, it was very helpful. Reviewing the code there appears to be a bug in the PBS job runner - in some cases pbs_job_state.stop_job is never set but is attempted to be read. I don't have torque so I don't have a great test setup for this problem, any chance you can make the following changes for me and let me know if they work?
Between the following two lines:
log.error( '(%s/%s) PBS job failed: %s' % ( galaxy_job_id, job_id, JOB_EXIT_STATUS.get( int( status.exit_status ), 'Unknown error: %s' % status.exit_status ) ) ) self.work_queue.put( ( self.fail_job, pbs_job_state ) )
log.error( '(%s/%s) PBS job failed: %s' % ( galaxy_job_id, job_id, JOB_EXIT_STATUS.get( int( status.exit_status ), 'Unknown error: %s' % status.exit_status ) ) ) pbs_job_state.stop_job = False self.work_queue.put( ( self.fail_job, pbs_job_state ) )
And at the top of the file can you add a -11 option to the JOB_EXIT_STATUS to indicate a job timeout.
I have attached a patch that would apply against the latest stable - it will probably will work against your branch as well.
If you would rather not act as my QC layer, I can try to come up with a way to do some testing on my end :).
Thanks again, -John
On Mon, Nov 4, 2013 at 10:10 AM, Daniel Patrick Sullivan <dansullivan@gmail.com> wrote:
Hi, Galaxy Developers,
I have what I hops is somewhat of a basic question regarding Galaxy's interaction with a pbs job cluster and information reported via the webUI. Basically, in certain situations, the walltime of a specific job is exceeded. This is of course to be expected and all fine and understandeable.
My problem is that the information is not being relayed back to the end user via the Galaxy web UI, which causes confusion in our Galaxy user community. Basically the Torque scheduler generates the following message when a walltime is exceeded:
11/04/2013
08:39:45;000d;PBS_Server.30621;Job;163.sctest.cri.uchicago.edu;preparing to send 'a' mail for job 163.sctest.cri.uchicago.edu to s.cri.galaxy@crigalaxy-test.uchicago.edu (Job exceeded its walltime limit. Job was aborted 11/04/2013 08:39:45;0009;PBS_Server.30621;Job;163.sctest.cri.uchicago.edu;job exit status -11 handled
Now, my problem is that this status -11 return code is not being correctly handled by Galaxy. What happens is that Galaxy throws an exception, specificially:
10.135.217.178 - - [04/Nov/2013:08:39:42 -0500] "GET /api/histories/90240358ebde1489 HTTP/1.1" 200 - "https://crigalaxy-test.uchicago.edu/history" "Mozilla/5.0 (X11; Linux x86_64; rv:23.0) Gecko/20100101 Firefox/23.0" galaxy.jobs.runners.pbs DEBUG 2013-11-04 08:39:46,137 (2150/163.sctest.cri.uchicago.edu) PBS job state changed from R to C galaxy.jobs.runners.pbs ERROR 2013-11-04 08:39:46,139 (2150/163.sctest.cri.uchicago.edu) PBS job failed: Unknown error: -11 galaxy.jobs.runners ERROR 2013-11-04 08:39:46,139 (unknown) Unhandled exception calling fail_job Traceback (most recent call last): File
"/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/__init__.py", line 60, in run_next method(arg) File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py", line 561, in fail_job if pbs_job_state.stop_job: AttributeError: 'AsynchronousJobState' object has no attribute 'stop_job'
After this exception occurs, the Galaxy job status via the Web UI is still reported as "Job is currently running". It appears that the job will remain in this state (from the end users perspective) indefinitely. Has anybody seen this issue before?
I noticed that return code -11 does not exist in /group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py under the JOB_EXIT_STATUS dictionary. I tried adding an entry for this, however when I do the exception changes to:
galaxy.jobs.runners.pbs ERROR 2013-11-04 10:02:17,274 (2151/164.sctest.cri.uchicago.edu) PBS job failed: job walltime exceeded galaxy.jobs.runners ERROR 2013-11-04 10:02:17,275 (unknown) Unhandled exception calling fail_job Traceback (most recent call last): File
"/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/__init__.py", line 60, in run_next method(arg) File "/group/galaxy_test/galaxy-dist/lib/galaxy/jobs/runners/pbs.py", line 562, in fail_job if pbs_job_state.stop_job: AttributeError: 'AsynchronousJobState' object has no attribute 'stop_job'
I am wondering if this is a bug or if it is just because I am using a newer version of TORQUE (I am using TORQUE 4.2.2).
In terms of Galaxy, I am using:
[s.cri.galaxy@crigalaxy-test galaxy-dist]$ hg parents changeset: 10408:6822f41bc9bb branch: stable parent: 10393:d05bf67aefa6 user: Dave Bouvier <dave@bx.psu.edu> date: Mon Aug 19 13:06:17 2013 -0400 summary: Fix for case where running functional tests might overwrite certain files in database/files.
[s.cri.galaxy@crigalaxy-test galaxy-dist]$
Does anybody know how I could fix this such that walltime exceeded messages are correctly reporeted via the Galaxy web UI for TORQUE 4.2.2? Thank you so much for your input and guidance, and for the ongoing development of Galaxy.
Dan Sullivan
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
participants (2)
-
 Daniel Patrick Sullivan
Daniel Patrick Sullivan -
 John Chilton
John Chilton