Queuing/Scheduling question (long)

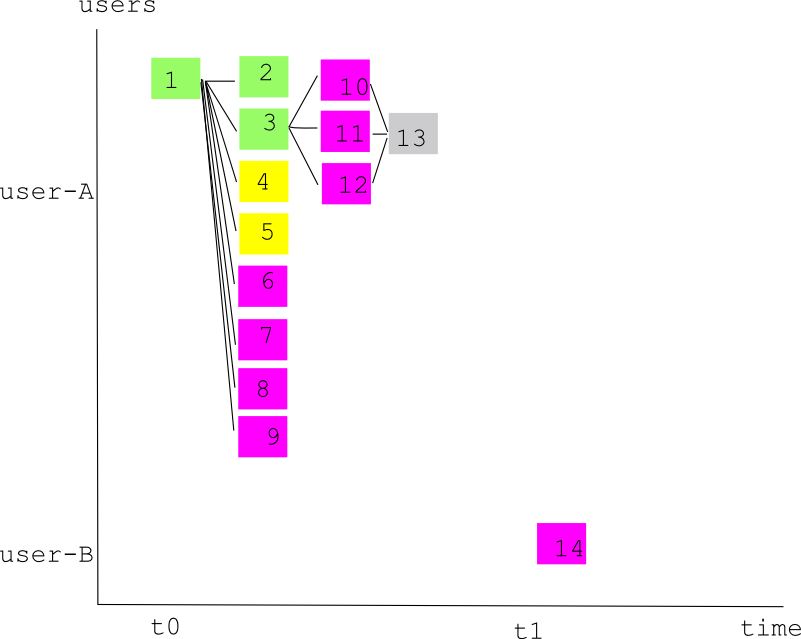
Hello, I have a question regarding the job queuing/scheduling in Galaxy, because although I assured my users that the scheduling is fair (using the "round robin" scheduler), what I'm seeing is not exactly fair (and so users wait a long time for their jobs to run). I'll try to explain the situation as best as I can, and I'll appreciate any feedback. The attached diagram shows a situation similar to what I have. At time "t0", user-A submits a workflow with many steps (the lines represent input-output connections, the numbers are job numbers). After a while, jobs 1,2,3 are done (green). and jobs 4,5 are running (yellow) - assuming I can run only two jobs at a time. If I understand correctly, jobs 6-12 are queued (i.e. their input dataset is "ready", so they are ready to run, and put on my local runner queue). Job 13 is still "new" because its input datasets (11,12,13) are not ready. At time "t1", (while jobs 4,5 are still running), user-B submits a single job (#14). If I understand correctly, it will go from "new" to "queued" immediately, because it isn't dependent on any input dataset and is ready to run. My question is: Once jobs 4 or 5 are completed, which job will run next ? If everything is "fair", I'd expect job #14 (from the second user) to run. But what I think I'm seeing, is that the "queued jobs" queue is actually FIFO, and jobs 6-12 will be run before job 14. (Job 14 however will run before job 13), Is the "round-robin" queue refers only to the transition from "new" to "queued" ? I could be completely wrong about this whole thing, but what I'm experiencing is that user-A submitted 5 workflows in parallel (all look very similar to the attached diagram), I have 7 runnings jobs (of user-A), 35 queued job from user-A and 2 queued job from user-B, and galaxy consistently chooses to run queued job from user-A instead of user-B (presumably because they were queued before user-B submitted the jobs). Is there a way to work around this issue ? a different configuration maybe ? Or, an old request: is it possible to limit the number of jobs-per-user at any single time (i.e. a single user can run 3 jobs at any given time, even if no other users are running jobs and there are 7 workers ready) ? Thanks for reading so far, -gordon
{kind=link}

I have 7 runnings jobs (of user-A), 35 queued job from user-A and 2 queued job from user-B, and galaxy consistently chooses to run queued job from user-A instead of user-B (presumably because they were queued before user-B submitted the jobs).
You've nailed it. The "queuing policy" determines the order in which the jobs are handed to the runner. If a user queues a bunch of jobs while no one else is waiting, and then another user comes along, they have to wait. This is definitely not ideal, however unless you are running *only* local job runners it is tricky to deal with because really it is the underlying queuing system that decides what order jobs actually get run in. However, I thought you were already mapping Galaxy users onto cluster users, which should result in the cluster scheduler dealing with some of these issues.
Is there a way to work around this issue ? a different configuration maybe ?
Or, an old request: is it possible to limit the number of jobs-per- user at any single time (i.e. a single user can run 3 jobs at any given time, even if no other users are running jobs and there are 7 workers ready) ?
I'd like to hear other suggestions, but I think some substantial rewriting is the only way to deal with this. Basically right now, the dispatcher has no notion of what is actually going on down in the runners. In particular, it doesn't know how many jobs the user already has running. We need to think about how to re-architect this. Fortunately, we're in the midst of a big rewrite of the job manager and scheduling, so this will definitely be something we work on. I'll try to think of an easy way to get the current framework to do what you want.
Hello James, Thanks for your reply. James Taylor wrote, On 01/21/2010 07:24 PM:
I have 7 runnings jobs (of user-A), 35 queued job from user-A and 2 queued job from user-B, and galaxy consistently chooses to run queued job from user-A instead of user-B (presumably because they were queued before user-B submitted the jobs).
You've nailed it. The "queuing policy" determines the order in which the jobs are handed to the runner. If a user queues a bunch of jobs while no one else is waiting, and then another user comes along, they have to wait.
I'd just like to make a small distinction:
From the user's point of view, there are only two states: "new" (i.e. not running) and "running". I'd expect (as a user) to have a fair-queuing, where all the "new" jobs are fairly executed among users.
Galaxy, Internally, has two "not running" states: "new" and "queued". The "new" jobs are scheduled fairly, the "queued" ones are not (they are FIFOed). While I'm in no position to say how things should work, I think a single queue that is fairly scheduled is preferable.
This is definitely not ideal, however unless you are running *only* local job runners it is tricky to deal with because really it is the underlying queuing system that decides what order jobs actually get run in.
Not sure I understand this, because my scheduling background is severely lacking. Why not (naively) assume that the underlying queuing system is FIFO, and make sure you submit the jobs to it in the order you want them executed (that is - fairly)? In a local-runner, we agree this is the correct solution. But for your PBS cluster, does it use something else than FIFO (based on the order that you run "qsub" from inside galaxy)? Do you have a way to tell your PBS from which session the job came, so it will fairly schedule them AFTER submission ? I could be missing something huge here, but aren't "queued" job being sent to PBS/SGE in FIFO order? meaning: jobs coming from a parallel workflow will still get ahead of queue.
However, I thought you were already mapping Galaxy users onto cluster users, which should result in the cluster scheduler dealing with some of these issues.
Not exactly. First, we still use local-runner for performance reasons, and plan to have only "heavy" jobs run on the cluster. Second, the patch I sent some time ago adds the user name as the job's name - allowing to keep track of which user started the job. But all the job would still run under my SGE account. (BTW, this is a huge selling point for our Galaxy - users can take advantage of the cluster easily, without actually having to ask for a cluster unix account).
Is there a way to work around this issue ? a different configuration maybe ?
Or, an old request: is it possible to limit the number of jobs-per-user at any single time (i.e. a single user can run 3 jobs at any given time, even if no other users are running jobs and there are 7 workers ready) ?
I'd like to hear other suggestions, but I think some substantial rewriting is the only way to deal with this. Fortunately, we're in the midst of a big rewrite of the job manager and scheduling, so this will definitely be something we work on.
If it's not to late to make some suggestions: 0. Fair-queuing everything The fairness criteria can be debated, but in any way avoid the current FIFO situation. 1. prioritize "interactive" jobs over "workflow" jobs. Reason: If a user submits a job 'interactively' (by running a single tool and clicking 'execute'), he usually expect to get an answer fast (unless it's a long mapping job). If the job is part of a workflow (especially a NGS related workflow), it is reasonable to assume the user doesn't expect it to complete immediately. (Sounds similar to the classical batch vs interactive scheduling on unix). This is a critical problem for my Galaxy server: some users use it interactively to investigate and 'play around' with data, running a job, looking at the output, changing a parameter, running it again, etc., etc. Other users upload five FASTQ files, start five 25-step workflows, and walk away - knowing that they'll have the results in a couple of hours. The "interactive" users are *very* frustrated (and rightfully so). 2. Create 'classes' of tools: light/medium/heavy (or similar). 'light' tools are prioritized over 'heavy' tools (heavy usually means CPU bound). Reason: Users who run light jobs (e.g. text tools, filter, join, visualization, simple interval operations) can expect them to complete faster than heavy jobs (like mapping or huge interval intersections). This is especially true when the jobs are interactive, but is also reasonable for jobs which are part of workflows. Of course - there are always the exceptions: a multi-column sort on a huge text file, or a mapping job on a tiny FASTA file. But the general rule holds (IMHO). A more complicated criteria: Some heuristics based on the "weight" of the tool and the size of the input dataset. The "weight" settings can be changed in tool_conf.xml or something similar. 3. Limit on number of jobs-per-user. Maybe not so critical for a big dedicated cluster, but crucial for a local-job-runner, and also for a cluster on which I have to "compete" for slots with other cluster (non-galaxy) users. If given the choice, I'd rather give up some perceived performance (a user on a idle galaxy can not use it fully with 20 parallel jobs) and gain better responsiveness (new users can always start jobs relatively fast). Sort of like through-put vs. latency. 4. Optional limit on jobs-per-tool. This might be too specialized, but it has occurred couple of times for me. Say there is a limited resource, and I've added a Galaxy tool to use that resource. Examples: a tool to upload files to a remote FTP (limited bandwidth), a tool to use special hardware devices, a tool that connects to a remote computer and runs something with SSH (and I don't want to over load that computer), a tool that requires 23GB or ram, and I have to run it locally on my 32GB ram server instead of the 8GB cluster nodes (but I can only run it once at a time). I'm aware that all of these problems can be solved by correctly installing a new SGE/PBS cluster manager and configuring a specialized queue, and configuring the scheduling of that queue - but to be honest: I don't want to be an SGE administrator. And some suggestions not related to queuing: 5. The ability to shutdown galaxy without losing jobs. I guess that with a cluster + job-recovery, you never lose jobs when you stop galaxy, but how do I do that with a local runner ? Maybe something like the "job-lock", which prevents new jobs from being started. I suggested a patch long ago, but now I realize it will not work with a multi-process environment, so something better is needed. Maybe unlike your public galaxy (which is very stable and not changed often), my local galaxy server is much less stable, we sometimes add several tools a week, we frequently add new genomes, we remove tools that don't work and replace them with newer versions, etc. I understand it's complicated to reload everything without stopping galaxy, so I need a way to stop and start it without causing too much damage to my users (or sending funny lab-wide emails asking: "please don't start any jobs this evening after 7pm"). 6. Track the time a job spend in each state (new/queue/running/metadata). 7. Better tracking of "external/internal metadata" state. Call me crazy ("Anal retentive" is also a word that comes to mind...), but I'm having hard time keeping track of jobs in the reports/unfinished_jobs page (and I do that all the time). Jobs are completed, their process doesn't appear in "ps", but their state is still "running" (or something else?). When I see the set-metadata scripts in "ps" - I want to know where they come from: which job, which user, everything. If it's a job like any other job, I want to know all about it. Especially if a set_metadata job takes minutes (and it does for large files) - Is that being counted somewhere ? If an external metadata job is run by other means (cloning histories?) I also want to know about it. In short, I need a report page that I can trust to show me exactly what is being executed right now. 8. Silly, but I think it's true: When a local-runner executes new processes, they inherit all of its open file descriptors, or at least the listening socket. So when my galaxy process is stopped while jobs are still running, the port is taken, and restarting galaxy fails with "socket bind" error. I need to kill the jobs and only then restart galaxy (and would much rather let them finish and set the dataset state manually to "OK"). (of course - galaxy should never crash or be stopped while jobs are running, but I can't help it). Maybe it's possible to close file descriptors before forking a new local process ? Thank you for reading so far, Galaxy is still great, so please don't take my rants the wrong way, -gordon

Gordon and James; Happy to see this discussion. Gordon's scheduling ideas mirror the conversations we've had here concerning wide release of compute intensive next gen tools. This isn't much more than a me too e-mail but wanted to highlight the two points we also discussed.
2. Create 'classes' of tools: light/medium/heavy (or similar). 'light' tools are prioritized over 'heavy' tools (heavy usually means CPU bound).
The light/heavy distinction is the number one idea thrown around here. We have a lot of custom tools that fall into the heavy category and are memory intensive such that they can only run on certain hardware and only a certain number of jobs can run concurrently. Having them fall into a separate queues with different limits would help with this type of custom scheduling.
3. Limit on number of jobs-per-user.
This is also a point of contention due to the perception of potential processor hogs backing up jobs for days or weeks by submitting several intensive jobs. It's mostly a control issue to satisfy people worried about worst possible case situations. Brad
participants (3)
-
 Assaf Gordon
Assaf Gordon -
 Brad Chapman
Brad Chapman -
 James Taylor
James Taylor