Not-So-Running Jobs

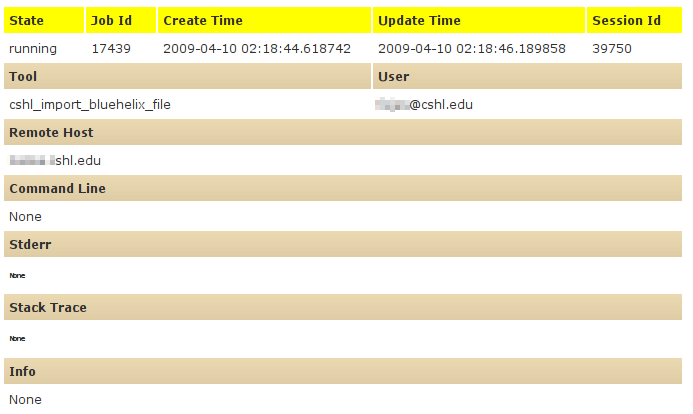
Hello, I've encountered a strange situation (at at least strange for me): Users are submitting jobs, and the jobs start almost immediately. However, the jobs look like they are running for very long time. Checking the report web page, a job looks like the attached image. The status is "running", but the command line is empty, and no program was executed for this job (I checked with "ps ax -H" and looked for python's child-processes). Some technical information: Running on Fedora with Python 2.4.3, PostgreSQL 8.0. The server is loaded but not too loaded ( 14.4 load average for 16 cores ). Relevant settings from universe_wsgi.ini: use_threadpool = true threadpool_workers = 10 local_job_queue_workers = 5 job_scheduler_policy = galaxy.jobs.schedulingpolicy.roundrobin:UserRoundRobin job_queue_cleanup_interval = 30 Is this normal ? Thanks, Gordon.
{kind=link}

Assaf Gordon wrote:
Users are submitting jobs, and the jobs start almost immediately. However, the jobs look like they are running for very long time. Checking the report web page, a job looks like the attached image.
The status is "running", but the command line is empty, and no program was executed for this job (I checked with "ps ax -H" and looked for python's child-processes).
Some technical information: Running on Fedora with Python 2.4.3, PostgreSQL 8.0.
The server is loaded but not too loaded ( 14.4 load average for 16 cores ).
Hi Gordon, Two config options could be the cause here: local_job_queue_workers (default: 5) cluster_job_queue_workers (default: 3) The local workers are the threads available for actually running jobs. To facilitate the ability for job tracking to occur in the database, jobs are moved to the 'running' state before execution. At that point, if there are not enough threads available, they may sit in the local job runner's queue until a thread becomes available. The cluster workers option defines the number of threads available to run the prepare/finish methods of jobs running via pbs/sge (and does not control the total number of jobs that can run - the cluster scheduler does that). Jobs with long finish methods (e.g. setting metadata on large datasets) could consume all of these threads, preventing new jobs from making it to the pbs/sge queue until threads are available. Switching to 'running' before execution is probably wrong, since they are not actually running. It probably makes sense to create a new job state for this limbo position. --nate
Thank you for the explanation. Continuing my limbo-jobs problems:
The status is "running", but the command line is empty, and no program was executed for this job (I checked with "ps ax -H" and looked for python's child-processes).
Two config options could be the cause here: local_job_queue_workers (default: 5)
The local workers are the threads available for actually running jobs. To facilitate the ability for job tracking to occur in the database, jobs are moved to the 'running' state before execution. At that point, if there are not enough threads available, they may sit in the local job runner's queue until a thread becomes available.
My Galaxy uses local scheduler with Round Robin policy ( and 5 local job queue workers). The "Unfinished jobs" report page shows 5 running jobs (really running with command line) and several other "limbo-running" jobs (and tons of "new" jobs). The problem is that the galaxy python process has only 4 child-processes (instead of the expected 5). I double checked by grepping for the command line that the "unfinished jobs" page shows - it doesn't exists in the processes list ($ ps ax -H). So it appears galaxy missed the termination of the job, and one queue worker will be forever lost. The only hint I have regarding this is that it was a long running job, and the user canceled it before it was completed (I actually can't tell if it was executed or just limbo-running). Is there a way to release the queue worker (besides restarting galaxy?) Thanks, Gordon.
Assaf Gordon wrote:
My Galaxy uses local scheduler with Round Robin policy ( and 5 local job queue workers).
The "Unfinished jobs" report page shows 5 running jobs (really running with command line) and several other "limbo-running" jobs (and tons of "new" jobs).
New jobs are dependent on other, running jobs and some backup can be expected (especially if waiting on early steps in a workflow).
The problem is that the galaxy python process has only 4 child-processes (instead of the expected 5).
I double checked by grepping for the command line that the "unfinished jobs" page shows - it doesn't exists in the processes list ($ ps ax -H).
So it appears galaxy missed the termination of the job, and one queue worker will be forever lost. The only hint I have regarding this is that it was a long running job, and the user canceled it before it was completed (I actually can't tell if it was executed or just limbo-running).
It's possible that the job is still running its finish method (perhaps a new 'finishing' state is also in order). This can be a lengthy process for large datasets where setting metadata is complex.
Is there a way to release the queue worker (besides restarting galaxy?)
Currently, no. --nate
participants (2)
-
 Assaf Gordon
Assaf Gordon -
 Nate Coraor
Nate Coraor