huge trees in library slow

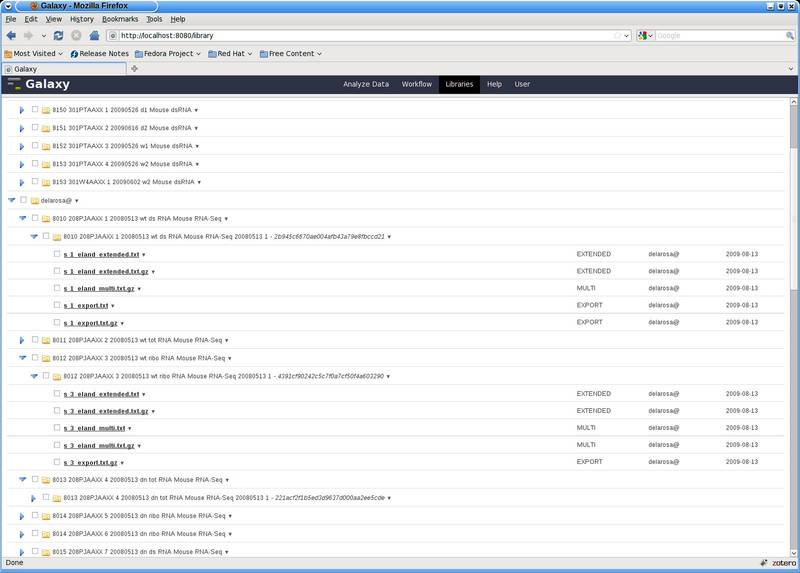
This is what my importer of our solexa runs currently creates: Structure of the tree: Currently each group (~8 ATM) has a library. Within each library each user has a folder, each sequenced sample of this user has a folder and within the folder of the sequenced sample each analysis (unique combination of image-analysis/basecall/alignment) has its own folder with some of the output files each as a dataset. At the moment I store the paths (not the files) from ~250 solexa samples in galaxy. Some samples are sequenced multiple times, for each run 4-5 files (I will also add some diagnostic files). In total there are now 1200 library datasets in the database (the paths that is). I have also tweaked the permission system a little bit. Each dataset has quite a lot of permissions associated with it. So the tree is not that big, but for galaxy/firefox its big. For one user it takes 20 seconds to bring up the library folder. Then a little bit more than one minute to bring up the tree (sometimes firefox thinks the script is hanging). But its still in development not production and I don't know how much speedup a change from sqlite to postgresql will bring. Of course I guess it will only get worse because its always more data that will come in. I don't know how to profile with python, but check_folder_contents in security/__init__.py could be one of the culprits. best wishes, ido
{kind=link}
participants (1)
-
 Ido M. Tamir
Ido M. Tamir