
Sorry for the confusion. That was a note to anyone that may be reading that has a very old (galaxy-dist revision f3c2243, 2011-11-15) that they should not apply the patch. Their error reporting controller would not work. Prior to that revision, a server-rendered history panel was used which (for some functionality) still used unencoded ids. That revision enabled the client-rendered history panel, which uses the encoded ids. You are very much in the clear re: that P.S. Carl On Wed, Mar 13, 2013 at 9:33 AM, Jean-Francois Payotte < jean-francois.payotte@dnalandmarks.ca> wrote:
Dear Carl,
I forgot to ask you something. In one of your previous mails, you said:
*PS. if user's are still using the older history panel - please, do not apply this patch as it relies on the older, raw ids for this function.
So, before applying the patch to our production Galaxy instance, I would like to know what you meant by "if users are still using the older history panel"? What exactly is the "older history panel"? Our galaxy instance is up to date with the latest revision (Feb 08, 2013), does that mean that I don't have to worry about the "older history panel"?
Thanks,
*Jean-Francois*
From: Jean-Francois Payotte <jean-francois.payotte@dnalandmarks.ca> To: carlfeberhard@gmail.com Cc: "galaxy-dev@lists.bx.psu.edu" <galaxy-dev@lists.bx.psu.edu> Date: 12/03/2013 12:40 PM Subject: Re: [galaxy-dev] Strange issue where the dataset reported in the bug report doesn't correspond to the current dataset Sent by: galaxy-dev-bounces@lists.bx.psu.edu ------------------------------
Hi Carl,
We are using a mysql database backend as well. Thank you for your help and do not hesitate if I can sen you any other useful information about our local Galaxy instance.
Thanks, * Jean-Francois*
From: Carl Eberhard <carlfeberhard@gmail.com> To: Jean-Francois Payotte <jean-francois.payotte@dnalandmarks.ca> Cc: John Chilton <chilton@msi.umn.edu>, " galaxy-dev@lists.bx.psu.edu" <galaxy-dev@lists.bx.psu.edu> Date: 12/03/2013 09:18 AM Subject: Re: [galaxy-dev] Strange issue where the dataset reported in the bug report doesn't correspond to the current dataset ------------------------------
1 & 2: Very interesting then. I'll do some more digging as to why a query would succeed (with the wrong record) with those ids.
3: Good!
4.1: That first line is just the beginning of the diff/patch file and not something you have to enter. It records the command used to generate the diff file. That revision was the revision I was updated to when generating the patch and, since I was using a development version more recently updated than your machine, your hg can't find it. There's no need to run that line, tho (see 4.2).
4.2: If you want to import a patch in the future, I've had good luck with 'hg import --no-commit <mypatchfile.patch>'. This will make the changes in the patch file without committing them ('--no-commit'). If you want to remove the changes later (and assuming you haven't made any other changes you want to keep in that file) you can use 'hg revert <thefilethatwaschanged.py>' and that will return the file to the previous state. Keep in mind, of course, that patches (like any changes) may make updating, and/or merging your instance later more difficult.
A question I forgot to ask: what database backend are you using (postgresql, mysql, etc.)?
Carl
On Mon, Mar 11, 2013 at 12:34 PM, Jean-Francois Payotte <* jean-francois.payotte@dnalandmarks.ca*<jean-francois.payotte@dnalandmarks.ca>> wrote: Dear Dannon, John and Carl,
Thank you for your answers and for taking the time to help me solve this issue. Here are my answers to your questions:
1. I don't think our number of HDAs is large enough to cause an overflow. From what I can see, the HDAs number in our two faulty galaxy instances are:
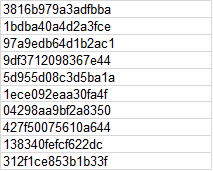
galaxy_prod : 263,163 HDAs galaxy_dev : 14,119 HDAs 2. Here is a list of hashed IDs for HDAs where I'm seeing this behaviour: (None of them are of 16-digit integers)
3. I've also tried applying John's patch on our development Galaxy instance and so far, *it seems to do the trick*. I've run my test tool (wich output a message to stderr) about 50 times, and the bug report always displayed the correct dataset. Yay!!
4. I would have two question though before applying the patch to our production Galaxy instance: 1. If I run the below "hg diff -r f25f3fee4da7 lib/galaxy/webapps/galaxy/controllers/dataset.py" command, I receive the following error:*
abort: unknown revision 'f25f3fee4da7'!*
Is this a normal behaviour? Are we missing something important?
2. Also, out of curiosity, is there a particular way to "apply" a patch (like the one you sent me), or if I simply have to manually edit the file? (That's what I did.)
Thanks again for your help! This is greatly appreciated! *
Jean-Francois*
From: Carl Eberhard <*carlfeberhard@gmail.com*<carlfeberhard@gmail.com>
To: John Chilton <*chilton@msi.umn.edu* <chilton@msi.umn.edu>> Cc: Jean-Francois Payotte <*jean-francois.payotte@dnalandmarks.ca*<jean-francois.payotte@dnalandmarks.ca>>, "*galaxy-dev@lists.bx.psu.edu* <galaxy-dev@lists.bx.psu.edu>" <* galaxy-dev@lists.bx.psu.edu* <galaxy-dev@lists.bx.psu.edu>> Date: 08/03/2013 06:07 PM Subject: Re: [galaxy-dev] Strange issue where the dataset reported in the bug report doesn't correspond to the current dataset ------------------------------
Hello,
We explored this for quite a while this afternoon and believe John is correct about the location as well as the design decision.
It may be that the hashes generated in some instances will correctly parse as 16 digit integers and, since an integer lookup is tried first (and you may either have an extraordinary large number of HDAs or there is some integer roll over/overflow - at a guess), the incorrect dataset is being returned without attempting to decode the hash into the proper dataset. This may also explain why it is consistent but intermittent.
I would be curious to see the hashed ids of the HDAs where you're seeing this behavior. Can you provide some?
If the hash produces fully integer strings as we're (tentatively) guessing, the if not str( id ).isdigit() may still branch improperly unfortunately.
In any event and to John's last point, from what we can tell, dataset.errors is only called from the new history panel and only encoded ids are used there - so the backwards compatibility may not be needed at this point.*
I will thoroughly check that that controller method isn't called elsewhere with a raw id, but, in the meantime: Jean-Francois, can you apply the patch below (and attached) to your more updated installation and (when convenient) see if that helps?
*PS. if user's are still using the older history panel - please, do not apply this patch as it relies on the older, raw ids for this function.
diff -r f25f3fee4da7 lib/galaxy/webapps/galaxy/controllers/dataset.py --- a/lib/galaxy/webapps/galaxy/controllers/dataset.py Fri Mar 08 16:01:25 2013 -0500 +++ b/lib/galaxy/webapps/galaxy/controllers/dataset.py Fri Mar 08 17:41:46 2013 -0500 @@ -171,14 +171,17 @@
@web.expose def errors( self, trans, id ): + hda = None try: - hda = trans.sa_session.query( model.HistoryDatasetAssociation ).get( id ) - except: - hda = None - if not hda: - hda = trans.sa_session.query( model.HistoryDatasetAssociation ).get( trans.security.decode_id( id ) ) + # only sent from the history panel (which uses encoded ids) + decoded_id = trans.security.decode_id( id ) + hda = trans.sa_session.query( model.HistoryDatasetAssociation ).get( decoded_id ) + except Exception, exc: + log.error( 'Could not retrieve hda with id "%s": %s', id, str( exc ), exc_info=True ) + if not hda or not self._can_access_dataset( trans, hda ): - return trans.show_error_message( "Either this dataset does not exist or you do not have permission to access it." ) + return trans.show_error_message( "Either this dataset does not exist " + + "or you do not have permission to access it." ) return trans.fill_template( "dataset/errors.mako", hda=hda )
@web.expose
On Fri, Mar 8, 2013 at 3:49 PM, John Chilton <*chilton@msi.umn.edu*<chilton@msi.umn.edu>> wrote: Does rewriting this:
def errors( self, trans, id ): try: hda = trans.sa_session.query( model.HistoryDatasetAssociation ).get( id ) except: hda = None if not hda: hda = trans.sa_session.query( model.HistoryDatasetAssociation ).get( trans.security.decode_id( id ) ) if not hda or not self._can_access_dataset( trans, hda ): return trans.show_error_message( "Either this dataset does not exist or you do not have permission to access it." ) return trans.fill_template( "dataset/errors.mako", hda=hda )
to say this:
def errors( self, trans, id ): if not str(id).isdigit(): id = trans.security.decode_id( id ) hda = trans.sa_session.query( model.HistoryDatasetAssociation ).get( id ) if not hda or not self._can_access_dataset( trans, hda ): return trans.show_error_message( "Either this dataset does not exist or you do not have permission to access it." ) return trans.fill_template( "dataset/errors.mako", hda=hda )
help the problem? Neither of these are particularly good design decisions. errors should either take in an id or an encoded id, or at least take them in as different parameters.
-John
-John
On Tue, Mar 5, 2013 at 12:38 PM, Jean-Francois Payotte <*jean-francois.payotte@dnalandmarks.ca*<jean-francois.payotte@dnalandmarks.ca>> wrote:
Dear Galaxy mailing-list,
I did some more tests in order to find out what might be causing this issue and it appears that we are facing this problem on two of our local Galaxy instances, which makes me think of a possible Galaxy bug rather than a database issue (both Galaxy instances using a different database). Does anybody else is facing this issue?
As a reminder, the issue we are currently facing is the "Dataset generation error" page displaying the wrong information (the information related to a completely different dataset) when clicking on the bug icon. (This is happening about half the time a tool ends in error).
Note that every time this issue occurs:
The stdout and stderr (displayed in the dataset peek window) are correct. The information displayed when clicking on "stdout" and "stderr" in the "view details" window is also correct. (It pertains to the actual dataset) The information displayed in the "Dataset generation errors" (the window displayed after clicking the bug icon) is incorrect. It relates to a completely different dataset.
I have attached a screenshot for better understanding (see dataset_generation_errors.jpg). In this picture, you can see a brand new history having only one dataset produced by my test tool (which only output a simple text to both stdout and stderr, which makes the dataset ends in error). In this picture, I have clicked on the bug icon of dataset 1 (the one and only dataset in the history), and you can see that the "Dataset generation error" page displays information about some Dataset 64: Compute sequence length on data 1, which makes no sense at all.
I've also looked in Galaxy database to see if the information was correctly recorded with the creation of my new dataset. Everything seems ok to me, the job is recorded with its proper stdout and stderr and all the IDs seems ok (I've looked at tables job, history, history_dataset_association, dataset).
My hypothesis regarding this issue, is that sometime, when clicking the bug icon, the wrong hda is sent to the "Dataset generation errors" page, hence the retrieval of information pertaining to a different dataset. I don't know why this happens but it is really frustrating because it makes debugging tools really difficult, having to refer to the database to have the complete and accurate error message.
We have 3 different instances of Galaxy running locally and we are experiencing this issue on two of them (both of them are now at the latest release, Feb 8th, 2013). The third instance has not been updated for a while (Sept. 7 2012 distribution) and does not have this problem.
I've tried to look into some Galaxy files and I found out that the function calling the "Dataset generation errors" page ("dataset/errors.mako") had some changes between the latest release and the Sept. 7th 2012 distribution. Maybe this have nothing to do at all with the bug, but just in case I thought I would mention it.
Latest release:
def errors( self, trans, id ): try: hda = trans.sa_session.query( model.HistoryDatasetAssociation ).get( id ) except: hda = None if not hda: hda = trans.sa_session.query( model.HistoryDatasetAssociation ).get( trans.security.decode_id( id ) ) if not hda or not self._can_access_dataset( trans, hda ): return trans.show_error_message( "Either this dataset does not exist or you do not have permission to access it." ) return trans.fill_template( "dataset/errors.mako", hda=hda )
Sept. 7 2012 distribution:
def errors( self, trans, id ): hda = trans.sa_session.query( model.HistoryDatasetAssociation ).get( id ) return trans.fill_template( "dataset/errors.mako", hda=hda )
If someone else is facing this issue or might have an idea of what's going on, please let me know.
Thank you, Jean-François
From: Jean-Francois Payotte <* jean-francois.payotte@dnalandmarks.ca*<jean-francois.payotte@dnalandmarks.ca>
To: *galaxy-dev@lists.bx.psu.edu* <galaxy-dev@lists.bx.psu.edu> Date: 27/02/2013 09:45 AM Subject: [galaxy-dev] Strange issue where the dataset reported in the bug report doesn't correspond to the current dataset Sent by: *galaxy-dev-bounces@lists.bx.psu.edu*<galaxy-dev-bounces@lists.bx.psu.edu> ________________________________
Dear Galaxy mailing-list,
We are currently facing a strange issue with our local Galaxy installation (distribution from Jan. 11 2013). I'm going to try to describe the problem as much as I can, and feel free to ask for more details if it can help in solving this issue.
So basically, we have a situation where (about half the time), when a job ends in error, the error message (shown when clicking on the bug icon), doesn't seem to be related to the dataset in error. As this particular problem seem to be present only when datasets ends in error, I created a simple python script which simply does 2 things: 1. It outputs the hostname to stdout (in order to investigate if the problem is node-dependant) 2. It outputs the following message "This is an error message printed to stderr", to stderr. (This is done in order to get only error datasets and to investigate the before-mentioned issue.)
Here is the code of my python script:
import sys import socket
def main(): print socket.gethostname() sys.stderr.write('This is an error message printed to stderr\n')
if __name__ == '__main__': main()
I ran this tool about 50 times and I looked at the error messages displayed both in the preview section of the dataset (in the history), and the error message displayed when clicking on the bug icon "view or report this error".
About half the time, the results were as expected:
the dataset stdout would read the name of the node where the job was executed the dataset stderr would read: "This is an error message printed to stderr" and the error message displayed when clicking on the bug icon would be:
Dataset generation errors
Dataset 54: Test error
Tool execution generated the following error message: This is an error message printed to stderr
The tool produced the following additional output: *some.server.name* <http://some.server.name/>
However, the other half of the time, the error message shown in stderr doesn't correspond to the error message displayed when clicking on the bug icon:
the dataset stdout is still reading the name of the node the dataset stderr is still reading "This is an error message printed to stderr" but the error message displayed when clicking on the bug icon would be something like:
Dataset generation errors
Dataset 3: chrM.bed
Tool execution did not generate any error messages.
We can clearly see a discrepancy between the error message in stderr and the error message of the bug report. Actually, the bug report is saying that there is not any error and it makes reference to some "Dataset 3: chrM.bed", even when the actual dataset is "Dataset 53: Test error". There is absolutely no .bed file in my history and the dataset 3 actually reads "Dataset 3: Test error". Some of the datasets mentioned in the faulty bug reports seems to be really old datasets (like one year old).
So my question to you is, could this be related to some mix-up between datasets ID? And how can I look this up. I must say that at the moment, I have absolutely no idea how to solve this issue.
Many thanks for your help!
Best regards, Jean-François ___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at:
*http://lists.bx.psu.edu/* <http://lists.bx.psu.edu/>
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at:
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at:
*http://lists.bx.psu.edu/* <http://lists.bx.psu.edu/> [attachment "dataset.errors_id.patch" deleted by Jean-Francois Payotte/NA/BASF] ___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at:
{kind=link}