
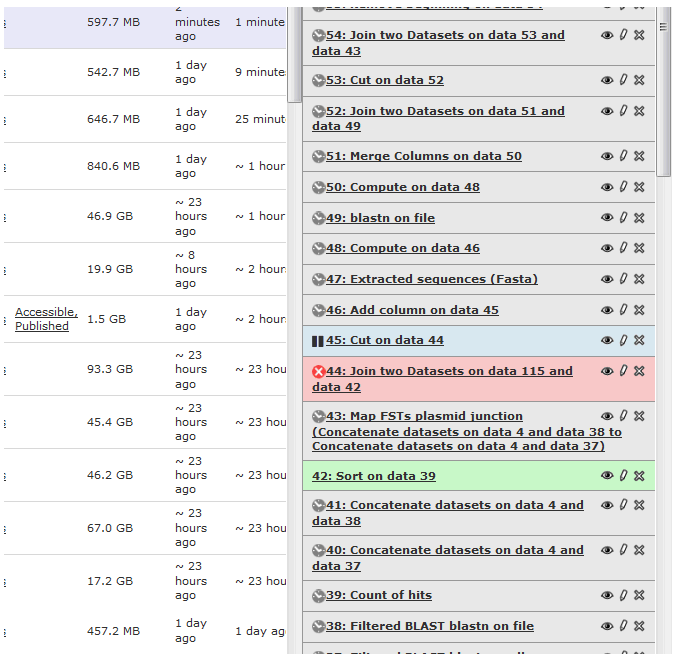
Dear Galaxy mailing list, I will be taking over this issue here now. Here is an update on this issue and our observations. I would like to know your insight on the matter if you can think of anything! We tried to revert back to a Galaxy instance running only one job handler. With that configuration, we observed that the out of order execution problem still occured, but MUCH less frequently than when using three handlers. On multiple workflow runs, only one job started while its input was not ready in only one run of the workflow. When using three job handlers, it occured on all workflow runs and on multiple jobs inside each workflow run. Our poweruser also noticed that his workflow, when taking too much time to prepare (which is always the case I think since it's a huge workflow), duplicates the history the same amount of times as the number of threadpool_workers we have configured for the job handlers. Now I am not sure both are related at all since I do not know much what is the effect of running a handler on multiple thread_workers. In any case, as of now we are staying with a single handler configuration since it in part fix the out of order execution problems, but since we have many regular users and some powerusers, that is not the ideal solution. Hope somebody can shed some light on this! Cheers! Yves Gagnon LIMS/ELN Developer Phone: +1 450 357-3370 Fax: +1 450 358-1154 E-Mail: yves.gagnon@dnalandmarks.ca Postal Address: DNA LandMarks Inc., 84 Rue Richelieu, Saint-Jean-Sur-Richelieu, Quebec, CANADA, J3B 6X3 DNA LandMarks - une compagnie de BASF Plant Science / a BASF Plant Science company Confidentiality notice: The information contained in this e-mail is confidential and may be the subject of legal professional privilege. It is intended for the authorized use of the individual or entity addressed. If the receiver or reader of this message is not the intended recipient, you are hereby notified that any disclosure, copying, distribution or use of the contents of this message is prohibited. If this email is received in error, please accept our apologies, delete all copies from your system, and notify us at support@dnalandmarks.ca.----Confidentialité: L'information contenue dans ce courriel est confidentielle et peut être assujettie aux règles concernant le secret professionel. L'information contenue dans ce courriel est autorisée uniquement pour l'individu ou l'entité légale adressée. Si le récipiendaire ou le lecteur de ce message n'est pas celui ou celle prévue, vous êtes tenu de ne pas présenter, copier, distribuer ou utiliser le contenu de ce message. Si ce courriel est reçu par erreur, veuillez nous en excuser, veuillez détruire toutes copies de votre système nous informer à support@dnalandmarks.ca. From: Jean-Francois Payotte <jean-francois.payotte@dnalandmarks.ca> To: galaxy-dev@lists.bx.psu.edu Date: 13/11/2013 11:12 AM Subject: Re: [galaxy-dev] Job execution order mixed-up Sent by: galaxy-dev-bounces@lists.bx.psu.edu Hi John, Thank you for your answer and for trying to help. This is greatly appreciated! I didn't really made any progress in tracking down this error, and hopefully this weird behaviour will not happen anymore with the November 4th, distribution. But here are my answers to your questions, in case it would ring a bell: 1. Has this behaviour been reported with any other workflow? It has been reported with 2 different workflows as of now. These 2 workflows doesn't have anything in common, except that they are huge (one of them has 37 steps, producing a total of about 110 datasets). 2. Are you running Galaxy as a single process or multiple processes? If multiple processes, how many web, handler and manager processes do you have and are they all on the same machine? We are running Galaxy in multiple processes with 5 web servers, 3 job handlers and no manager (I believe the manager was rendered obsolete in one of the latest Galaxy distributions). All these processes are run on the same machine. 3. Have you made any modifications to Galaxy that could result in this behaviour? No. 4. What is the value of track_jobs_in_database in your universe_wsgi.ini configuration file? We never touched this part of the configuration file and the line still reads: "#track_jobs_in_database = None". After reading your answer, I've decided to modify this line to: "track_jobs_in_database = True" Unfortunately, running one of the faulty workflows several times (5x), I noticed that one of them was still showing this strange behaviour where some jobs were executed before their inputs were ready. Do you think this issue could be related to the fact that we are using Galaxy with the multiple processes configuration? We implemented this configuration some time ago because some of our users were complaining about the slow responsiveness of the web interface. Would you recommend using Galaxy without the multiple processes configuration? (Lets say if updating to November 4th distribution doesn't fix this issue) I guess you are probably using the multiple processes configuration as well on Galaxy main? Thanks again for your help! Jean-François ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Posted by John Chilton on Nov 09, 2013; 2:50pm Hello Jean-François, Have you made any progress tracking down this error? This appears very serious, but to tell you the truth I have no clue what could cause it. The distribution you are using is pretty old at this point I feel like if it was a bug the exhibited under relatively standard parameter combinations someone else would have reported it by now. Can you tell me some things: has this been reported with any other workflows? Is there anything special about this workflow? Can you rebuild the workflow and see if the error occurs again? Additional questions if the problem is not restricted to the workflow: are you running Galaxy as a single process or multiple processes? If multiple processes, how many web, handler, and manager processes do you have? Are they all on the same machine? Have you made any modifications to Galaxy that could result in this behavior? What is the value of track_jobs_in_database in your universe_wsgi.ini configuration file? -John On Thu, Nov 7, 2013 at 10:34 AM, Jean-Francois Payotte <[hidden email]> wrote: Dear Galaxy mailing-list, Once again I come seeking for your help. I hope someone already had this issue or will have an idea on where to look to solve it. :) One of our users reported having workflows failing because some steps were executed before all their inputs where ready. You can find a screenshot attached, where we can see that step (42) "Sort on data 39" has been executed while step (39) is still waiting to run (gray box). This behaviour has been reproduced with at least two different Galaxy tools (one custom, and the sort tool which comes standard with Galaxy). This behaviour seems to be a little bit random, as running two times a workflow where this issue occurs, only one time did some steps were executed in the wrong order. I could be wrong, but I don't think this issue is grid-related as, from my understanding, Galaxy is not using SGE job dependencies functionality. I believe all jobs stays in some internal queues (within Galaxy) until all input files are ready, and only then the job is submitted to the cluster. Any help or any hint on what to look at to solve this issue would be greatly appreciated. We have updated our Galaxy instance to August 12th distribution on October 1st, and I believe we never experienced this issue before the update. Many thanks for your help, Jean-François ___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/ To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
{kind=link}