
Hi, something strange happens with Cufflinks in our Galaxy server. When a user deletes a running Cufflinks job in fact the associated Cufflinks process(es) are not terminated. Apart from unneccessary CPU usage, this prevents other jobs from starting if the max jobs limit has been already reached by the user. This happens only with Cufflinks, Cuffcompare for comparison behaves just fine. Best, F. -- ============================================ Federico Zambelli, Ph.D. Bioinformatics, Evolution and Comparative Genomics Lab Dept. of Biosciences University of Milano - Italy What can be asserted without proof can be dismissed without proof. ============================================

On Tue, Feb 18, 2014 at 2:20 PM, Federico Zambelli <federico.zambelli@unimi.it> wrote:
Hi,
something strange happens with Cufflinks in our Galaxy server. When a user deletes a running Cufflinks job in fact the associated Cufflinks process(es) are not terminated. Apart from unneccessary CPU usage, this prevents other jobs from starting if the max jobs limit has been already reached by the user.
This happens only with Cufflinks, Cuffcompare for comparison behaves just fine.
Best, F.
What cluster system are you using? Can you try a few other long running tools for comparison? I've been meaning to double check if this still happens, but I had seen this for BLAST+ jobs under SGE (noticeable again when large zombie jobs are blocking the queue). Peter
Hi Peter, it runs on a single server since this Galaxy instance is for internal use of our lab only. Aborting other long running tools like tophat and bowtie works just as expected. I have also noticed that at least a couple of times not only the cufflinks process(es) were not terminated but also that one of the Galaxy handler processes (five of them in our instance) crashed. I suspect that the two things are related but have no proof for that. F. Il 18/02/14 15:24, Peter Cock ha scritto:
On Tue, Feb 18, 2014 at 2:20 PM, Federico Zambelli <federico.zambelli@unimi.it> wrote:
Hi,
something strange happens with Cufflinks in our Galaxy server. When a user deletes a running Cufflinks job in fact the associated Cufflinks process(es) are not terminated. Apart from unneccessary CPU usage, this prevents other jobs from starting if the max jobs limit has been already reached by the user.
This happens only with Cufflinks, Cuffcompare for comparison behaves just fine.
Best, F.
What cluster system are you using? Can you try a few other long running tools for comparison?
I've been meaning to double check if this still happens, but I had seen this for BLAST+ jobs under SGE (noticeable again when large zombie jobs are blocking the queue).
Peter
-- ============================================ Federico Zambelli, Ph.D. Bioinformatics, Evolution and Comparative Genomics Lab Dept. of Biosciences University of Milano - Italy What can be asserted without proof can be dismissed without proof. ============================================

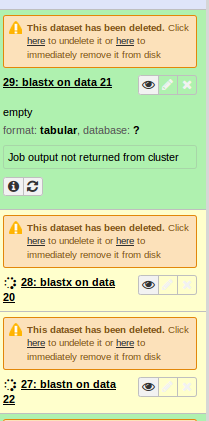
Hi, I can also see that behaviour under SGE long running jobs, like blast+. Screenshot attached. Cheers, Bjoern
On Tue, Feb 18, 2014 at 2:20 PM, Federico Zambelli <federico.zambelli@unimi.it> wrote:
Hi,
something strange happens with Cufflinks in our Galaxy server. When a user deletes a running Cufflinks job in fact the associated Cufflinks process(es) are not terminated. Apart from unneccessary CPU usage, this prevents other jobs from starting if the max jobs limit has been already reached by the user.
This happens only with Cufflinks, Cuffcompare for comparison behaves just fine.
Best, F. What cluster system are you using? Can you try a few other long running tools for comparison?
I've been meaning to double check if this still happens, but I had seen this for BLAST+ jobs under SGE (noticeable again when large zombie jobs are blocking the queue).
Peter ___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
{kind=link}
Hi, I have one running at the moment, that job is also not listed in the jobs monitor under the admin-panel. Cheers, Bjoern
On Tue, Feb 18, 2014 at 2:20 PM, Federico Zambelli <federico.zambelli@unimi.it> wrote:
Hi,
something strange happens with Cufflinks in our Galaxy server. When a user deletes a running Cufflinks job in fact the associated Cufflinks process(es) are not terminated. Apart from unneccessary CPU usage, this prevents other jobs from starting if the max jobs limit has been already reached by the user.
This happens only with Cufflinks, Cuffcompare for comparison behaves just fine.
Best, F. What cluster system are you using? Can you try a few other long running tools for comparison?
I've been meaning to double check if this still happens, but I had seen this for BLAST+ jobs under SGE (noticeable again when large zombie jobs are blocking the queue).
Peter ___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/

Hi all, There was a regression introduced in the most recent stable release that was preventing jobs from being stopped, fixed here: https://bitbucket.org/galaxy/galaxy-central/commits/1298d3f6aca59825d0eb3d32... You can pull from the stable branch of galaxy-central to get that changeset. If that doesn't resolve the problem, it sounds like it may be due to the crashing handlers, so we would need to figure out the cause of those crashes. --nate On Sat, Feb 22, 2014 at 12:24 PM, Björn Grüning <bjoern.gruening@gmail.com>wrote:
Hi,
I have one running at the moment, that job is also not listed in the jobs monitor under the admin-panel.
Cheers, Bjoern
On Tue, Feb 18, 2014 at 2:20 PM, Federico Zambelli
<federico.zambelli@unimi.it> wrote:
Hi,
something strange happens with Cufflinks in our Galaxy server. When a user deletes a running Cufflinks job in fact the associated Cufflinks process(es) are not terminated. Apart from unneccessary CPU usage, this prevents other jobs from starting if the max jobs limit has been already reached by the user.
This happens only with Cufflinks, Cuffcompare for comparison behaves just fine.
Best, F.
What cluster system are you using? Can you try a few other long running tools for comparison?
I've been meaning to double check if this still happens, but I had seen this for BLAST+ jobs under SGE (noticeable again when large zombie jobs are blocking the queue).
Peter ___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
Hi Nate, I'm running changeset: 12641:cab3db6e1d59 and I can see the same behaviour. The blast job is not listed under jobs in the admin section and I can't kill it, also not via deleting the dataset. Anything I can do to track that down? In my case it's a large blast job with splitting enabled. Cheers, Bjoern
Hi all,
There was a regression introduced in the most recent stable release that was preventing jobs from being stopped, fixed here:
https://bitbucket.org/galaxy/galaxy-central/commits/1298d3f6aca59825d0eb3d32...
You can pull from the stable branch of galaxy-central to get that changeset. If that doesn't resolve the problem, it sounds like it may be due to the crashing handlers, so we would need to figure out the cause of those crashes.
--nate
On Sat, Feb 22, 2014 at 12:24 PM, Björn Grüning <bjoern.gruening@gmail.com>wrote:
Hi,
I have one running at the moment, that job is also not listed in the jobs monitor under the admin-panel.
Cheers, Bjoern
On Tue, Feb 18, 2014 at 2:20 PM, Federico Zambelli
<federico.zambelli@unimi.it> wrote:
Hi,
something strange happens with Cufflinks in our Galaxy server. When a user deletes a running Cufflinks job in fact the associated Cufflinks process(es) are not terminated. Apart from unneccessary CPU usage, this prevents other jobs from starting if the max jobs limit has been already reached by the user.
This happens only with Cufflinks, Cuffcompare for comparison behaves just fine.
Best, F.
What cluster system are you using? Can you try a few other long running tools for comparison?
I've been meaning to double check if this still happens, but I had seen this for BLAST+ jobs under SGE (noticeable again when large zombie jobs are blocking the queue).
Peter ___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
Hi Björn, Does stopping other, non-split jobs work correctly for you? --nate On Wed, Feb 26, 2014 at 7:30 AM, Björn Grüning <bjoern.gruening@gmail.com>wrote:
Hi Nate,
I'm running
changeset: 12641:cab3db6e1d59
and I can see the same behaviour. The blast job is not listed under jobs in the admin section and I can't kill it, also not via deleting the dataset.
Anything I can do to track that down? In my case it's a large blast job with splitting enabled.
Cheers, Bjoern
Hi all,
There was a regression introduced in the most recent stable release that was preventing jobs from being stopped, fixed here:
https://bitbucket.org/galaxy/galaxy-central/commits/ 1298d3f6aca59825d0eb3d32afd5686c4b1b9294?at=stable
You can pull from the stable branch of galaxy-central to get that changeset. If that doesn't resolve the problem, it sounds like it may be due to the crashing handlers, so we would need to figure out the cause of those crashes.
--nate
On Sat, Feb 22, 2014 at 12:24 PM, Björn Grüning <bjoern.gruening@gmail.com>wrote:
Hi,
I have one running at the moment, that job is also not listed in the jobs monitor under the admin-panel.
Cheers, Bjoern
On Tue, Feb 18, 2014 at 2:20 PM, Federico Zambelli
<federico.zambelli@unimi.it> wrote:
Hi,
something strange happens with Cufflinks in our Galaxy server. When a user deletes a running Cufflinks job in fact the associated Cufflinks process(es) are not terminated. Apart from unneccessary CPU usage, this prevents other jobs from starting if the max jobs limit has been already reached by the user.
This happens only with Cufflinks, Cuffcompare for comparison behaves just fine.
Best, F.
What cluster system are you using? Can you try a few other long
running tools for comparison?
I've been meaning to double check if this still happens, but I had seen this for BLAST+ jobs under SGE (noticeable again when large zombie jobs are blocking the queue).
Peter ___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
Hi Nate, I can kill other jobs and other jobs are also showing up under "Job list". Not sure if it something related to job splitting, but I only encountered it with Blast. Thanks, Bjoern
Hi Björn,
Does stopping other, non-split jobs work correctly for you?
--nate
On Wed, Feb 26, 2014 at 7:30 AM, Björn Grüning <bjoern.gruening@gmail.com>wrote:
Hi Nate,
I'm running
changeset: 12641:cab3db6e1d59
and I can see the same behaviour. The blast job is not listed under jobs in the admin section and I can't kill it, also not via deleting the dataset.
Anything I can do to track that down? In my case it's a large blast job with splitting enabled.
Cheers, Bjoern
Hi all,
There was a regression introduced in the most recent stable release that was preventing jobs from being stopped, fixed here:
https://bitbucket.org/galaxy/galaxy-central/commits/ 1298d3f6aca59825d0eb3d32afd5686c4b1b9294?at=stable
You can pull from the stable branch of galaxy-central to get that changeset. If that doesn't resolve the problem, it sounds like it may be due to the crashing handlers, so we would need to figure out the cause of those crashes.
--nate
On Sat, Feb 22, 2014 at 12:24 PM, Björn Grüning <bjoern.gruening@gmail.com>wrote:
Hi,
I have one running at the moment, that job is also not listed in the jobs monitor under the admin-panel.
Cheers, Bjoern
On Tue, Feb 18, 2014 at 2:20 PM, Federico Zambelli
<federico.zambelli@unimi.it> wrote:
Hi,
something strange happens with Cufflinks in our Galaxy server. When a user deletes a running Cufflinks job in fact the associated Cufflinks process(es) are not terminated. Apart from unneccessary CPU usage, this prevents other jobs from starting if the max jobs limit has been already reached by the user.
This happens only with Cufflinks, Cuffcompare for comparison behaves just fine.
Best, F.
What cluster system are you using? Can you try a few other long
running tools for comparison?
I've been meaning to double check if this still happens, but I had seen this for BLAST+ jobs under SGE (noticeable again when large zombie jobs are blocking the queue).
Peter ___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
___________________________________________________________ Please keep all replies on the list by using "reply all" in your mail client. To manage your subscriptions to this and other Galaxy lists, please use the interface at: http://lists.bx.psu.edu/
To search Galaxy mailing lists use the unified search at: http://galaxyproject.org/search/mailinglists/
participants (4)
-
 Björn Grüning
Björn Grüning -
 Federico Zambelli
Federico Zambelli -
 Nate Coraor
Nate Coraor -
 Peter Cock
Peter Cock