Suggestion: new tag in tool's XML file (long)

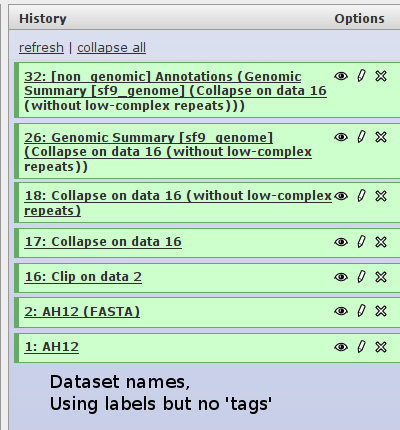
Hello, As recently discussed on this mailing list, With long workflows it becomes somewhat difficult to make sense of the datasets names. The 'label' option in the <output> tag is good start, but there's still room for improvement. I propose a new 'tag' element which might help a little bit. Here's an example: I have five tools in a simple workflow: Starting with a FASTQ file, FASTQ-to-FASTA FASTA-clipper, FASTA-collapser, FASTA-filter-by-length, FASTA-low-complexity-repeats-remover. Each tool has an <output> option with a label. The label takes the description of the tool, and the name of the input. Example from the low-complexity-repeats-remove tool: <output> <data format="input" name="output" label="$input.name (without low-complexity repeats)" metadata_source="input" /> </output> Similarly, most of the other tools have a 'label' option in the XML file. The problem is that after running the workflow, the name of each dataset becomes longer and longer, and more cumbersome. Even if I start with a very short name for the initial FASTQ file (e.g. 'AG14'), The other datasets are named like: AG14 (Fasta), AG14 (Fasta) clipped, AG14 (Fasta) clipped collapsed, Filter sequences by length on data 5 Filter sequences by length on data 5 (without low complexity repeats) (The filter-sequences-by-length tool doesn't have a 'label' option with makes the output even worse.) My suggestion: I would like each data set to have a 'tag' - a short name which is carried over from one dataset to the next, without taking the entire dataset's name. This 'tag' is usually just the name of the initial dataset. going back to the previous example, if I use the initial library name as the tag (=AG14), the output of the workflow would look like: AG14 AG14 (Fasta) AG14 (Clipped) AG14 (Collapsed) AG14 (Filtered Sequences) AG14 (without low complexity repeats) I tried to add this functionality to the galaxy source code. I'm aware that the Right Thing to do is probably to add a new column to the relevant database table, and setup the tools to automatically take the tag from one dataset to the next. However, as an intermediate solution, my hack works nicely (I'm attaching pictures of 'before' and 'after :-) ). With this hack, one can use the following 'label' in the XML <output> tag: <outputs> <data format="input" name="output" label="$input.tag clipped" metadata_source="input" /> </outputs> The "$input.tag" extract the tag from the input's name, and puts in the square brackets, so that the next tool will also be able to extract the tag. Here's the added code ( ./lib/galaxy/model/__init__.py ): ... class HistoryDatasetAssociation( object ): ... @property def tag ( self ): #Hack by gordon: #add a '.tag' attribute tag_match = re.search( '\[([^[]+)\]', self.name); if tag_match: tag = "[" + tag_match.group(1) + "]" ; else: tag = "[" + self.name + "]" ; return tag Thanks for reading so far, Any comments and welcomed, Gordon.
{kind=link}
{kind=link}
participants (1)
-
 Assaf Gordon
Assaf Gordon